はじめに

言語処理100本ノックは東北大学が公開している自然言語処理の問題集です。
とても良質なコンテンツで企業の研修や勉強会で使われています。
そんな言語処理100本ノックが2020年に改定されてました。昨今の状況を鑑みて、深層ニューラルネットワークに関する問題が追加されました。(その他にも細かい変更があります)
この記事では、言語処理100本ノック2020にPythonで取り組んでいきます。
他にも色々な解法があると思うので、一つの解答例としてご活用ください!
全100問の解説に戻る
準備
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
cabochaをインストールしていない方はインストールしておいて下さい。Macの場合、下記のコマンドでOKです。
1 | brew install cabocha |
リンクからneko.txtをダウンロードして、下記のコマンドを実行します。
1 | cabocha -f1 < neko.txt > neko.txt.cabocha |
これで準備完了です。
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,CaboChaの解析結果(neko.txt.cabocha)を読み込み,各文をMorphオブジェクトのリストとして表現し,3文目の形態素列を表示せよ.
1 | class Morph: |
EOSや解析結果(先頭が*から始まる)などの特殊な行に注意しましょう。
41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストのCaboChaの解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,8文目の文節の文字列と係り先を表示せよ.第5章の残りの問題では,ここで作ったプログラムを活用せよ.
1 | class Morph: |
係り先文節インデックス番号(dst)は解析結果として得られているのでそのまま利用すれば良いですが、係り元文節インデックス番号のリスト(srcs)は自前で用意する必要があります。
そこでdstの集計と並行して、srcs[dst]を作成します。この時点では文節の数が不明なので、必要に応じてsrcsをextendします。
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
1 | import itertools |
itertools.chain.from_iterableを使って二次元リストを一次元リストに変換している。
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
1 | import itertools |
クラスChunkに以下のインスタンス変数を追加しました。
1 | self.has_noun = False |
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい
準備
今回はpydotを利用した。必要があればインストールする。
1 | pip install pydot |
pydotはgraphvizのインターフェイスを提供するものなので、graphviz本体も必要があればインストールする。
1 | brew install graphviz |
pydotの基本
公式の情報が見当たりませんでしたので、こちらを参考にさせていただきました。
グラフの構築
1 | graph = pydot.Dot() |
1 | graph = pydot.Dot(graph_type='digraph') # 有向グラフ |
1 | graph = pydot.Dot(graph_type='graph') # # 無向グラフ |
ノードの追加
1 | node_a = pydot.Node("Node A") |
エッジの追加
1 | graph.add_edge(pydot.Edge(node_a, node_b)) |
グラフを画像として保存
1 | graph.write_png('output.png') |
コード
1 | import itertools |
下記のような画像が出力されれば成功です。
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える. この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
1 | 始める で |
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
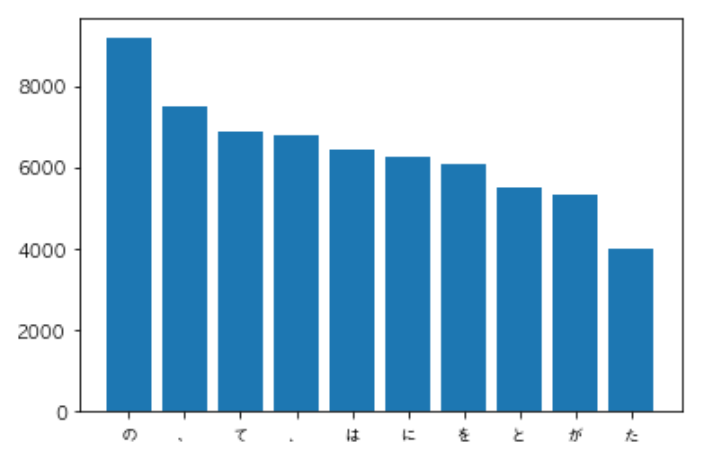
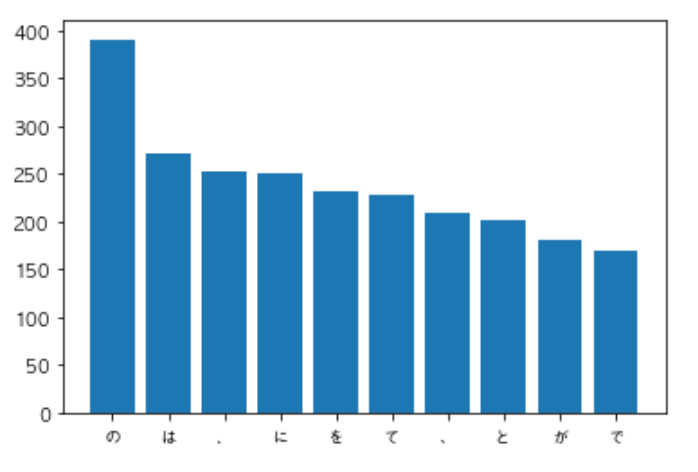
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
コード
1 | import itertools |
確認
1 | sort 45.txt | uniq -c | sort -n -r | head |
1 | 417 云う と |
1 | grep "^する\t" 45.txt | sort | uniq -c | sort -n -r | head |
1 | 256 する を |
1 | grep "^見る\t" 45.txt | sort | uniq -c | sort -n -r | head |
1 | 156 見る て |
1 | grep "^与える\t" 45.txt | sort | uniq -c | sort -n -r | head |
1 | 3 与える に を |
46. 動詞の格フレーム情報の抽出
45のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.45の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える. この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
1 | 始める で ここで |
コード
1 | import itertools |
47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする
- 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
例えば「別段くるにも及ばんさと、主人は手紙に返事をする。」という文から,以下の出力が得られるはずである.
1 | 返事をする と に は 及ばんさと 手紙に 主人は |
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語(サ変接続名詞+を+動詞)
- コーパス中で頻出する述語と助詞パターン
コード
1 | import itertools |
文節をまたいで、サ変接続名詞+を(助詞)扱うためにグローバル変数sahen_woを用意しましたが、もう少し良い方法がありそうです。
1 | cut -f 1 47.txt | sort | uniq -c | sort -n -r | head |
1 | 26 返事をする |
1 | cut -f 1,2 47.txt | sort | uniq -c | sort -n -r | head |
1 | 6 返事をする と |
48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を” -> “で連結する
「吾輩はここで始めて人間というものを見た」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
1 | 吾輩は -> 見た |
コード
1 | import itertools |
再帰関数recを導入した。
49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がiとj(i<j)のとき,係り受けパスは以下の仕様を満たすものとする
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を” -> “で連結して表現する
- 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示
- 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合: 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパス,文節kの内容を” | “で連結して表示
例えば,「吾輩はここで始めて人間というものを見た。」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
1 | Xは | Yで -> 始めて -> 人間という -> ものを | 見た |
1 | import itertools |
最後に
全100問の解説に戻る
記事情報
- 投稿日:2020年5月9日
- 最終更新日:2020年5月9日