N, Q = map(int, input().split()) A = list(map(int, input().split())) X = list(map(int, input().split()))
deftwo_pointers(x): left = 0 sm = 0 ans = 0 for right in range(N): sm += A[right] while(sm > x): sm -= A[left] left += 1 ans += (right-left+1) # leftに対する条件を満たすパターン数 return ans
SM = [] SN = [] M = int(input()) # 探したい星座 for m in range(M): x, y = map(int,input().split()) SM.append((x,y)) N = int(input()) # 星空の写真 for n in range(N): x, y = map(int,input().split()) SN.append((x,y)) st = set(SN) # inが高速 base = SM[0] # 探したい星座のうち基準となる星を設定 for sn in SN: dx, dy = sn[0]-base[0], sn[1]-base[1] # 平行移動の方法 ok = True for sm in SM: ifnot (sm[0]+dx, sm[1]+dy) in st: # さらに高速化 O(MN) ok = False break if (ok): print (dx,dy) exit() print (ans)
from itertools import permutations K = int(input()) N = 8 RC = [] for k in range(K): r, c = map(int,input().split()) RC.append((r,c))
defdiag(board):# 斜めの判定 for i in range(2*N-1): sm = 0 for j in range(i+1): if (i-j>=8or j>=8): continue sm += board[i-j][j] if sm > 1: returnFalse returnTrue
defjudge(ls): board = [[0]*N for _ in range(N)] for r in range(N): c = ls[r] board[r][c] = 1 for r, c in RC: # 指定された箇所にクイーンを置いているか判定 if board[r][c] == 0: returnFalse ifnot diag(board): returnFalse ifnot diag(board[::-1]): # 反転 returnFalse returnTrue
for ls in permutations(range(N)): if judge(ls): for c in ls: s = ['.'] * N s[c] = 'Q' print (''.join(s)) exit()
defwrite_X(file_name, df): with open(file_name,'w') as f: for text in df.iloc[:,1]: vectors = [] for word in text.split(): if word in model.vocab: vectors.append(model[word]) if (len(vectors)==0): vector = np.zeros(300) else: vectors = np.array(vectors) vector = vectors.mean(axis=0) vector = vector.astype(np.str).tolist() output = ' '.join(vector)+'\n' f.write(output) write_X('X_train.txt', train) write_X('X_valid.txt', valid) write_X('X_test.txt', test)
for epoch in range(10): for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = model(X_train) loss = loss_fn(y_pred, y_train) writer.add_scalar('Loss/train', loss, epoch) writer.add_scalar('Accuracy/train', accuracy(y_pred,y_train), epoch)
for epoch in range(10): for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = model(X_train) loss = loss_fn(y_pred, y_train) writer.add_scalar('Loss/train', loss, epoch) writer.add_scalar('Accuracy/train', accuracy(y_pred,y_train), epoch)
import time from torch.utils.data import TensorDataset, DataLoader classLogisticRegression(torch.nn.Module): def__init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(300, 4), ) defforward(self, X): return self.net(X)
model = LogisticRegression() ds = TensorDataset(X_train, y_train) loss_fn = torch.nn.CrossEntropyLoss()
ls_bs = [2**i for i in range(15)] ls_time = [] for bs in ls_bs: loader = DataLoader(ds, batch_size=bs, shuffle=True) optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(1): start = time.time() for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() ls_time.append(time.time()-start) print (ls_time)
ls_bs = [2**i for i in range(15)] ls_time = [] for bs in ls_bs: loader = DataLoader(ds, batch_size=bs, shuffle=True) optimizer = torch.optim.SGD(model.net.parameters(), lr=1e-1) for epoch in range(1): start = time.time() for xx, yy in loader: y_pred = model(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() ls_time.append(time.time()-start) print (ls_time)
Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル(300万単語・フレーズ,300次元)をダウンロードし,”United States”の単語ベクトルを表示せよ.ただし,”United States”は内部的には”United_States”と表現されていることに注意せよ.
with open('questions-words.txt') as f: questions = f.readlines() with open('64.txt','w') as f: for i,question in enumerate(questions): words = question.split() if len(words)==4: ans = model.most_similar(positive=[words[1],words[2]], negative=[words[0]],topn=1)[0] words += [ans[0], str(ans[1])] output = ' '.join(words)+'\n' else: output = question f.write(output) if (i%100==0): print (i)
cnt = 0 ok = 0 with open('64.txt','r') as f: questions = f.readlines() for question in questions: words = question.split() if len(words)==6: cnt += 1 if (words[3]==words[4]): ok +=1 print (ok/cnt)
66. WordSimilarity-353での評価
The WordSimilarity-353 Test Collectionの評価データをダウンロードし,単語ベクトルにより計算される類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
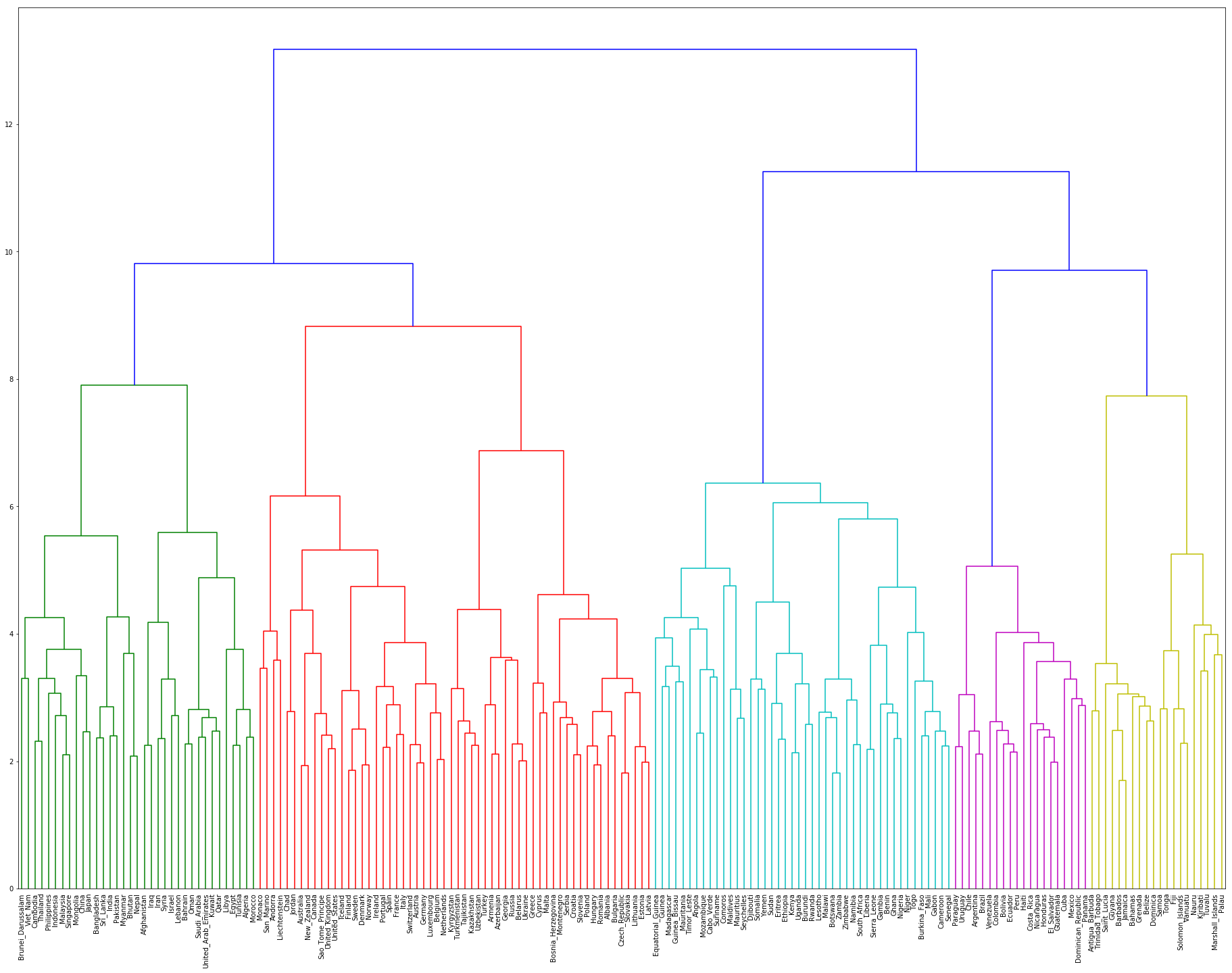
from sklearn.cluster import KMeans with open('country.txt','r') as f: lines = f.readlines() countries = [] for line in lines: country = line.split(' ')[-1].replace('\n','') countries.append(country) dic = {'United States of America':'United_States', 'Russian Federation':'Russia'} ng = 0 vec = [] target_countries = [] for c in countries: for k,v in dic.items(): c = c.replace(k,v) c = c.replace(' ','_').replace('-','_').replace('_and_','_') try: vec.append(model[c]) target_countries.append(c) except: ng += 1 kmeans = KMeans(n_clusters=5, random_state=0) kmeans.fit(vec) for c,l in zip(target_countries, kmeans.labels_): print (c,l)
import matplotlib.pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage plt.figure(figsize=(32.0, 24.0)) link = linkage(vec, method='ward') dendrogram(link, labels=target_countries,leaf_rotation=90,leaf_font_size=10) plt.show()
69. t-SNEによる可視化
国名に関する単語ベクトルのベクトル空間をt-SNEで可視化せよ.
コード
t-sneもsklearnを使うと良いです。
1 2 3 4 5 6 7
from sklearn.manifold import TSNE vec_embedded = TSNE(n_components=2).fit_transform(vec) vec_embedded_t = list(zip(*vec_embedded)) # 転置 fig, ax = plt.subplots(figsize=(16, 12)) plt.scatter(*vec_embedded_t) for i, c in enumerate(target_countries): ax.annotate(c, (vec_embedded[i][0],vec_embedded[i][1]))
dic = {'b':'business', 't':'science and technology', 'e' : 'entertainment', 'm' : 'health'} defpredict(text): text = [text] X = vectorizer.transform(text) ls_proba = clf.predict_proba(X) for proba in ls_proba: for c, p in zip(clf.classes_, proba): print (dic[c]+':',p) s = train_df.iloc[0]['TITLE'] print(s) predict(s)