はじめに
言語処理100本ノック は東北大学が公開している自然言語処理の問題集です。
とても良質なコンテンツで企業の研修や勉強会で使われています。
そんな言語処理100本ノックが2020年に改定されてました。昨今の状況を鑑みて、深層ニューラルネットワークに関する問題が追加されました。(その他にも細かい変更があります)
この記事では、言語処理100本ノック2020にPythonで取り組んでいきます。
他にも色々な解法があると思うので、一つの解答例としてご活用ください!
全100問の解説 に戻る
本章では,Fabio Gasparetti氏が公開しているNews Aggregator Data Setを用い,ニュース記事の見出しを「ビジネス」「科学技術」「エンターテイメント」「健康」のカテゴリに分類するタスク(カテゴリ分類)に取り組む.
50. データの入手・整形 News Aggregator Data Setをダウンロードし、以下の要領で学習データ(train.txt),検証データ(valid.txt),評価データ(test.txt)を作成せよ.
ダウンロードしたzipファイルを解凍し,readme.txtの説明を読む. 情報源(publisher)が”Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”の事例(記事)のみを抽出する. 抽出された事例をランダムに並び替える. 抽出された事例の80%を学習データ,残りの10%ずつを検証データと評価データに分割し,それぞれtrain.txt,valid.txt,test.txtというファイル名で保存する.ファイルには,1行に1事例を書き出すこととし,カテゴリ名と記事見出しのタブ区切り形式とせよ(このファイルは後に問題70で再利用する).
学習データと評価データを作成したら,各カテゴリの事例数を確認せよ.
コード pandasを使うと良いです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import pandas as pdfrom sklearn.model_selection import train_test_splitfrom functools import reducenews_corpora = pd.read_csv('NewsAggregatorDataset/newsCorpora.csv' ,sep='\t' ,header=None ) news_corpora.columns = ['ID' ,'TITLE' ,'URL' ,'PUBLISHER' ,'CATEGORY' ,'STORY' ,'HOSTNAME' ,'TIMESTAMP' ] publisher = ['Reuters' , 'Huffington Post' , 'Businessweek' , 'Contactmusic.com' , 'Daily Mail' ] ls_is_specified = [news_corpora.PUBLISHER == p for p in publisher] is_specified =reduce(lambda a, b: a | b, ls_is_specified) df = news_corpora[is_specified] df = df.sample(frac=1 ) train_df, valid_test_df = train_test_split(df, test_size=0.2 ) valid_df, test_df = train_test_split(valid_test_df, test_size=0.5 ) train_df.to_csv('train.txt' , columns = ['CATEGORY' ,'TITLE' ], sep='\t' ,header=False , index=False ) valid_df.to_csv('valid.txt' , columns = ['CATEGORY' ,'TITLE' ], sep='\t' ,header=False , index=False ) test_df.to_csv('test.txt' , columns = ['CATEGORY' ,'TITLE' ], sep='\t' ,header=False , index=False ) df['CATEGORY' ].value_counts()
51. 特徴量抽出 学習データ,検証データ,評価データから特徴量を抽出し,それぞれtrain.feature.txt,valid.feature.txt,test.feature.txtというファイル名で保存せよ. なお,カテゴリ分類に有用そうな特徴量は各自で自由に設計せよ.記事の見出しを単語列に変換したものが最低限のベースラインとなるであろう.
コード scikit-learnのCountVectorizerを使いました。単語を数え上げて特徴量を生成します。ベースラインとして適当だと思います。
1 2 3 4 5 6 7 8 9 from sklearn.feature_extraction.text import CountVectorizerimport numpy as npvectorizer = CountVectorizer() X_train = vectorizer.fit_transform(train_df['TITLE' ]) X_valid = vectorizer.transform(valid_df['TITLE' ]) X_test = vectorizer.transform(test_df['TITLE' ]) np.savetxt('train.feature.txt' , X_train.toarray(), fmt='%d' ) np.savetxt('valid.feature.txt' , X_valid.toarray(), fmt='%d' ) np.savetxt('test.feature.txt' , X_test.toarray(), fmt='%d' )
52. 学習 51で構築した学習データを用いて,ロジスティック回帰モデルを学習せよ.
コード scikit-learnに実装されているので、それを利用すると簡単です。
1 2 3 from sklearn.linear_model import LogisticRegressionclf = LogisticRegression() clf.fit(X_train, train_df['CATEGORY' ])
53. 予測 52で学習したロジスティック回帰モデルを用い,与えられた記事見出しからカテゴリとその予測確率を計算するプログラムを実装せよ.
コード predict_probaで各カテゴリの確率を取得することができます。
1 2 3 4 5 6 7 8 9 10 11 dic = {'b' :'business' , 't' :'science and technology' , 'e' : 'entertainment' , 'm' : 'health' } def predict (text) : text = [text] X = vectorizer.transform(text) ls_proba = clf.predict_proba(X) for proba in ls_proba: for c, p in zip(clf.classes_, proba): print (dic[c]+':' ,p) s = train_df.iloc[0 ]['TITLE' ] print(s) predict(s)
54. 正解率の計測 52で学習したロジスティック回帰モデルの正解率を,学習データおよび評価データ上で計測せよ.
コード 正解率を求める際はaccuracy_scoreを使います。
1 2 3 4 5 6 7 from sklearn.metrics import accuracy_scorey_train_pred = clf.predict(X_train) y_test_pred = clf.predict(X_test) y_train = train_df['CATEGORY' ] y_test = test_df['CATEGORY' ] print (accuracy_score(y_train, y_train_pred))print (accuracy_score(y_test, y_test_pred))
55. 混同行列の作成 52で学習したロジスティック回帰モデルの混同行列(confusion matrix)を,学習データおよび評価データ上で作成せよ.
コード confusion_matrixを用います。明示的にラベルの順序を指定することができます。
1 2 3 from sklearn.metrics import confusion_matrixprint (confusion_matrix(y_train, y_train_pred, labels=['b' ,'t' ,'e' ,'m' ]))print (confusion_matrix(y_test, y_test_pred, labels=['b' ,'t' ,'e' ,'m' ]))
56. 適合率,再現率,F1スコアの計測 52で学習したロジスティック回帰モデルの適合率,再現率,F1スコアを,評価データ上で計測せよ.カテゴリごとに適合率,再現率,F1スコアを求め,カテゴリごとの性能をマイクロ平均(micro-average)とマクロ平均(macro-average)で統合せよ.
コード precision_score,recall_score,f1_scoreを用います。引数averageとしてNoneを指定した場合はカテゴリ毎にリストで返却、micro,macroを指定した場合はそれぞれマイクロ平均とマクロ平均が返却されます。
1 2 3 4 5 6 7 8 9 10 11 12 from sklearn.metrics import precision_scorefrom sklearn.metrics import recall_scorefrom sklearn.metrics import f1_scoreprint (precision_score(y_test, y_test_pred, average=None , labels=['b' ,'t' ,'e' ,'m' ]))print (recall_score(y_test, y_test_pred, average=None , labels=['b' ,'t' ,'e' ,'m' ]))print (f1_score(y_test, y_test_pred, average=None , labels=['b' ,'t' ,'e' ,'m' ]))print (precision_score(y_test, y_test_pred, average='micro' , labels=['b' ,'t' ,'e' ,'m' ]))print (recall_score(y_test, y_test_pred, average='micro' , labels=['b' ,'t' ,'e' ,'m' ]))print (f1_score(y_test, y_test_pred, average='micro' , labels=['b' ,'t' ,'e' ,'m' ]))print (precision_score(y_test, y_test_pred, average='macro' , labels=['b' ,'t' ,'e' ,'m' ]))print (recall_score(y_test, y_test_pred, average='macro' , labels=['b' ,'t' ,'e' ,'m' ]))print (f1_score(y_test, y_test_pred, average='macro' , labels=['b' ,'t' ,'e' ,'m' ]))
57. 特徴量の重みの確認 52で学習したロジスティック回帰モデルの中で,重みの高い特徴量トップ10と,重みの低い特徴量トップ10を確認せよ.
コード インスタンス名.coef_とすることで、パラメータ(重み)を取得することができます。
1 2 3 4 5 6 7 names = np.array(vectorizer.get_feature_names()) labels=['b' ,'t' ,'e' ,'m' ] for c, coef in zip(clf.classes_, clf.coef_): idx = np.argsort(coef)[::-1 ] print (dic[c]) print (names[idx][:10 ]) print (names[idx][-10 :][::-1 ])
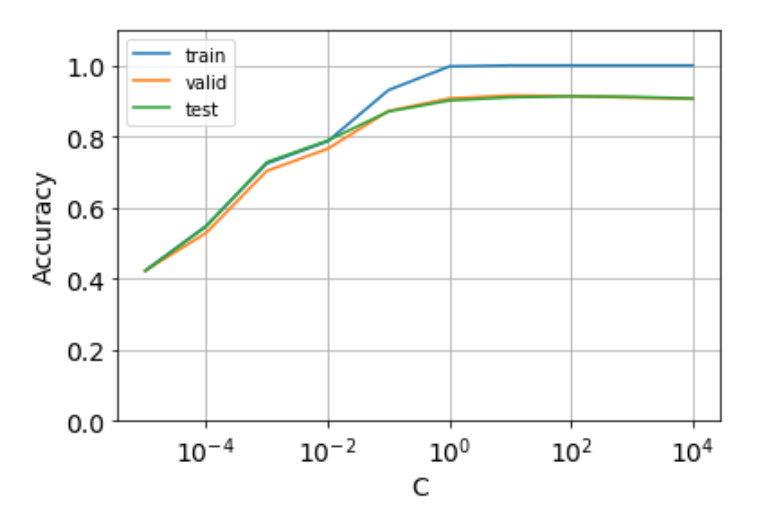
58. 正則化パラメータの変更 ロジスティック回帰モデルを学習するとき,正則化パラメータを調整することで,学習時の過学習(overfitting)の度合いを制御できる.異なる正則化パラメータでロジスティック回帰モデルを学習し,学習データ,検証データ,および評価データ上の正解率を求めよ.実験の結果は,正則化パラメータを横軸,正解率を縦軸としたグラフにまとめよ.
コード LogisticRegressionは正則化パラメータCを指定することができます。この値が小さいほど、強い正則化がかかります。
公式リファレンス
等比数列の作成には、numpy.logspaceが便利です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import matplotlib.pyplot as pltdef calc_scores (c) : y_train = train_df['CATEGORY' ] y_valid = valid_df['CATEGORY' ] y_test = test_df['CATEGORY' ] clf = LogisticRegression(C=c) clf.fit(X_train, y_train) y_train_pred = clf.predict(X_train) y_valid_pred = clf.predict(X_valid) y_test_pred = clf.predict(X_test) scores = [] scores.append(accuracy_score(y_train, y_train_pred)) scores.append(accuracy_score(y_valid, y_valid_pred)) scores.append(accuracy_score(y_test, y_test_pred)) return scores C = np.logspace(-5 , 4 , 10 , base=10 ) scores = [] for c in C: scores.append(calc_scores(c)) scores = np.array(scores).T labels = ['train' , 'valid' , 'test' ] for score, label in zip(scores,labels): plt.plot(C, score, label=label) plt.ylim(0 , 1.1 ) plt.xscale('log' ) plt.xlabel('C' , fontsize = 14 ) plt.ylabel('Accuracy' , fontsize = 14 ) plt.tick_params(labelsize=14 ) plt.grid(True ) plt.legend()
59. ハイパーパラメータの探索 学習アルゴリズムや学習パラメータを変えながら,カテゴリ分類モデルを学習せよ.検証データ上の正解率が最も高くなる学習アルゴリズム・パラメータを求めよ.また,その学習アルゴリズム・パラメータを用いたときの評価データ上の正解率を求めよ.
コード 正則化パラメータC以外のハイパーパラメータとして、solver(学習アルゴリズム)やclass_weight(クラス毎の重みづけ)を指定できます。
グリッドサーチを行いたいですが、GridSearchCVはクロスバリデーションを前提としているため利用できません。そこでitertools.productで各ハイパーパラメータの組み合わせを作成しました。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import itertoolsdef calc_scores (C,solver,class_weight) : y_train = train_df['CATEGORY' ] y_valid = valid_df['CATEGORY' ] y_test = test_df['CATEGORY' ] clf = LogisticRegression(C=C, solver=solver, class_weight=class_weight) clf.fit(X_train, y_train) y_train_pred = clf.predict(X_train) y_valid_pred = clf.predict(X_valid) y_test_pred = clf.predict(X_test) scores = [] scores.append(accuracy_score(y_train, y_train_pred)) scores.append(accuracy_score(y_valid, y_valid_pred)) scores.append(accuracy_score(y_test, y_test_pred)) return scores C = np.logspace(-5 , 4 , 10 , base=10 ) solver = ['newton-cg' , 'lbfgs' , 'liblinear' , 'sag' , 'saga' ] class_weight = [None , 'balanced' ] best_parameter = None best_scores = None max_valid_score = 0 for c, s, w in itertools.product(C, solver, class_weight): print(c, s, w) scores = calc_scores(c, s, w) if scores[1 ] > max_valid_score: max_valid_score = scores[1 ] best_parameter = [c, s, w] best_scores = scores print ('best patameter: ' , best_parameter)print ('best scores: ' , best_scores)print ('test accuracy: ' , best_scores[2 ])
最後に 全100問の解説 に戻る
関連書籍 本章で出てきたscikit-learnに関する内容は以下の書籍で勉強すると良いかと思います。
リンク
記事情報
投稿日:2020年5月9日
最終更新日:2020年7月31日