はじめに

言語処理100本ノックは東北大学が公開している自然言語処理の問題集です。
とても良質なコンテンツで企業の研修や勉強会で使われています。
そんな言語処理100本ノックが2020年に改定されてました。昨今の状況を鑑みて、深層ニューラルネットワークに関する問題が追加されました。(その他にも細かい変更があります)
この記事では、言語処理100本ノック2020にPythonで取り組んでいきます。
他にも色々な解法があると思うので、一つの解答例としてご活用ください!
全100問の解説に戻る
単語の意味を実ベクトルで表現する単語ベクトル(単語埋め込み)に関して,以下の処理を行うプログラムを作成せよ.
60. 単語ベクトルの読み込みと表示
Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル(300万単語・フレーズ,300次元)をダウンロードし,”United States”の単語ベクトルを表示せよ.ただし,”United States”は内部的には”United_States”と表現されていることに注意せよ.
コード
gensimはPythonのライブラリでトピックモデルやNLPの用途で利用されます。この記事ではgensimを使って学習済み単語ベクトルを扱おうと思います。
1 | import gensim |
61. 単語の類似度
“United States”と”U.S.”のコサイン類似度を計算せよ.
コード
similarityを利用します。
1 | model.similarity('United_States','U.S.') |
62. 類似度の高い単語10件
“United States”とコサイン類似度が高い10語と,その類似度を出力せよ.
コード
most_similarを利用します。デフォルトで上位10件を返却します。
1 | model.most_similar('United_States',topn=10) |
63. 加法構成性によるアナロジー
“Spain”の単語ベクトルから”Madrid”のベクトルを引き,”Athens”のベクトルを足したベクトルを計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.positive,negativeを指定することで加算や減算が可能です。
コード
1 | model.most_similar(positive=['Spain','Athens'], negative=['Madrid'],topn=10) |
64. アナロジーデータでの実験
単語アナロジーの評価データをダウンロードし,vec(2列目の単語) - vec(1列目の単語) + vec(3列目の単語)を計算し,そのベクトルと類似度が最も高い単語と,その類似度を求めよ.求めた単語と類似度は,各事例の末尾に追記せよ.
コード
私の環境では処理に一時間程度かかりました。
1 | with open('questions-words.txt') as f: |
65. アナロジータスクでの正解率
64の実行結果を用い,意味的アナロジー(semantic analogy)と文法的アナロジー(syntactic analogy)の正解率を測定せよ.
先ほど出力したファイルを読み込み、適当なカラム同士を比較します。
コード
1 | cnt = 0 |
66. WordSimilarity-353での評価
The WordSimilarity-353 Test Collectionの評価データをダウンロードし,単語ベクトルにより計算される類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
コード
set1とset2を結合したcombined.csvを利用すれば良いです。スピアマンの順位相関係数はpandasで計算できます。
1 | import pandas as pd |
67. k-meansクラスタリング
国名に関する単語ベクトルを抽出し,k-meansクラスタリングをクラスタ数k=5として実行せよ.
コード
国名のリストはこちらを利用しました。テキストファイルにコピペして、一部改行の修正をしました。
学習済みの語彙とは表記が一致していない国も多く、対応できるように置換を行いましたが、全ての国に対応している訳ではありません。
k-meansクラスタリングにはsklearnを利用しました。
1 | from sklearn.cluster import KMeans |
68. Ward法によるクラスタリング
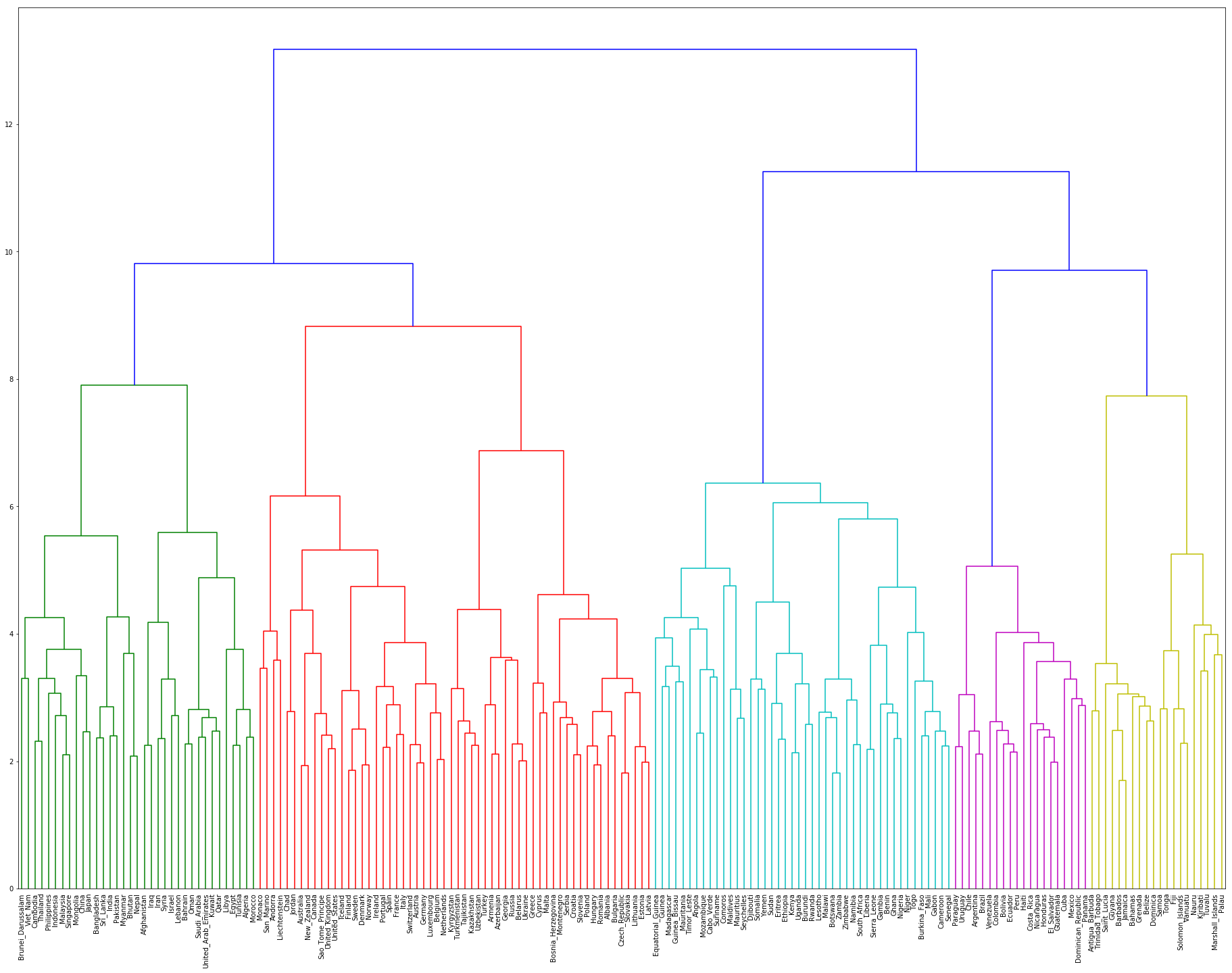
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
コード
デンドログラムを作成する際は、scipyを使うと良いでしょう。国名が多いので、文字が潰れないように工夫が必要です。
1 | import matplotlib.pyplot as plt |
69. t-SNEによる可視化
国名に関する単語ベクトルのベクトル空間をt-SNEで可視化せよ.
コード
t-sneもsklearnを使うと良いです。
1 | from sklearn.manifold import TSNE |

続きはまた明日!
最後に
全100問の解説に戻る
記事情報
- 投稿日:2020年5月9日
- 最終更新日:2020年5月9日