path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d)
path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d) [d['surface'] for d in result if d['pos'] == '動詞' ]
表層形は、baseをキーにして格納されています。
32. 動詞の原形
動詞の原形をすべて抽出せよ.
1 2 3 4 5 6 7 8 9 10 11 12 13
path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d) [d['base'] for d in result if d['pos'] == '動詞' ]
原形は、baseをキーにして格納されています。
33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d) noun_phrase = [] for i in range(len(result)-2): if (result[i]['pos'] == '名詞'and result[i+1]['surface'] == 'の'and result[i+2]['pos'] == '名詞'): noun_phrase.append(result[i]['surface']+result[i+1]['surface']+result[i+2]['surface']) print (noun_phrase)
path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d)
ls_noun = [] noun = '' for d in result: if d['pos']=='名詞': noun += d['surface'] else: if noun != '': ls_noun.append(noun) noun = '' else: if noun != '': ls_noun.append(noun) noun = '' print (ls_noun)
名詞を連結して貯めておき、名詞以外が出現したらリストに追加しています。
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from collections import Counter path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d)
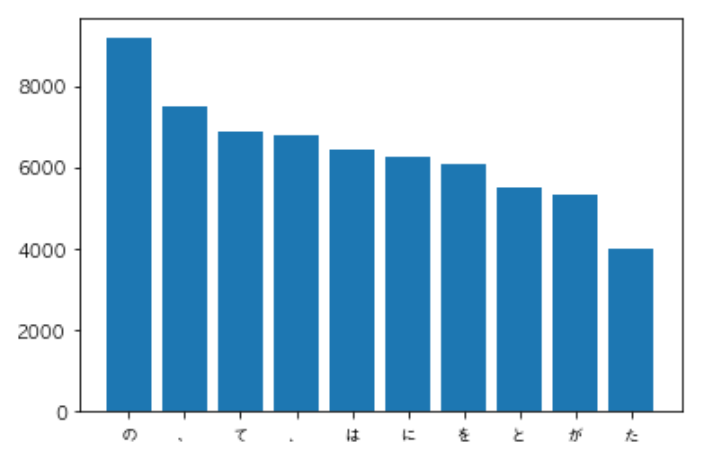
surface = [d['surface'] for d in result] c = Counter(surface) print (c.most_common())
from collections import Counter import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'AppleGothic' path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d)
surface = [d['surface'] for d in result] c = Counter(surface) target = list(zip(*c.most_common(10))) plt.bar(*target) plt.show()
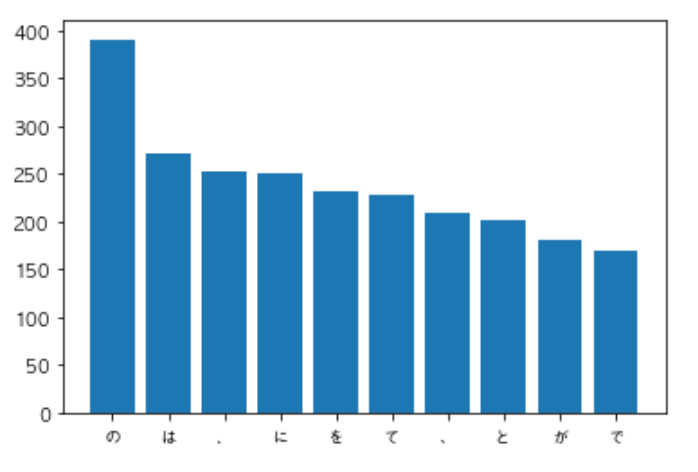
from collections import Counter import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'AppleGothic' path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] tmp_cooccurrence = [] cooccurrence = [] inCat = False
for line in text[:-1]: if line == 'EOS': if inCat: cooccurrence.extend(tmp_cooccurrence) else: pass tmp_cooccurrence = [] inCat = False continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d) if ls[0]!='猫': tmp_cooccurrence.append(ls[0]) else: inCat = True
c = Counter(cooccurrence) target = list(zip(*c.most_common(10))) plt.bar(*target) plt.show()
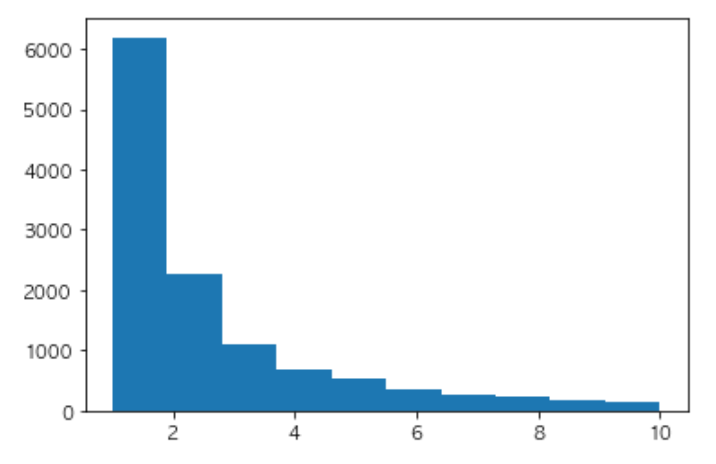
from collections import Counter import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'AppleGothic' path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d)
surface = [d['surface'] for d in result] c = Counter(surface) plt.hist(c.values(), range = (1,10)) plt.show()
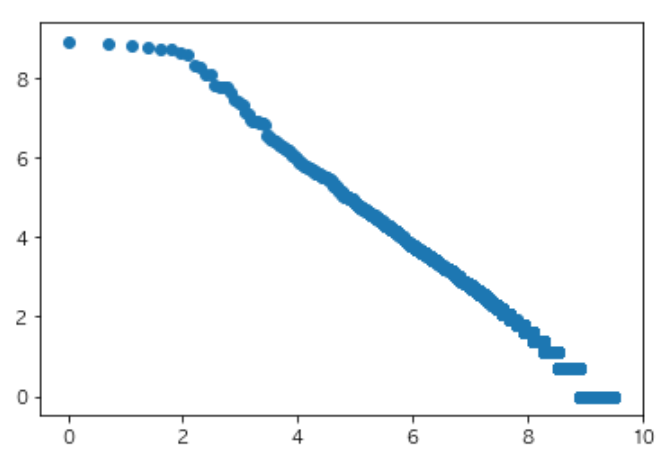
from collections import Counter import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.family'] = 'AppleGothic' path = 'neko.txt.mecab' with open(path) as f: text = f.read().split('\n') result = [] for line in text[:-1]: if line == 'EOS': continue ls = line.split('\t') d = {} tmp = ls[1].split(',') d = {'surface':ls[0], 'base':tmp[6], 'pos':tmp[0], 'pos1':tmp[1]} result.append(d) surface = [d['surface'] for d in result] c = Counter(surface) v = [kv[1] for kv in c.most_common()] plt.scatter(np.log(range(len(v))),np.log(v)) plt.show()