はじめに
この記事は、連載「ゼロから始める機械学習」 の5本目の記事となります。

前回「ロジスティック回帰」 では、アヤメの分類タスクを機械学習で解きました。
モデルには、NumPyで実装したロジスティック回帰を用いました。
前回残った課題
最後に述べたとおり
評価は未知のデータで行うべきであるにも関わらず、
学習と評価を同じデータを用いていましたね。
そこで、今回は学習データとテストデータについて考えていきます。
データの分割
そこで、評価のために未知のデータを用意したいところですが、
未知のデータで評価をすることは原理的にできませんね。
そこで、既存のデータを分割し一部を未知のデータとして扱います。これをテストデータと呼びます。一方で、残ったデータを学習用に用います。これを学習データと呼びます。
表にまとめると以下のようになります。
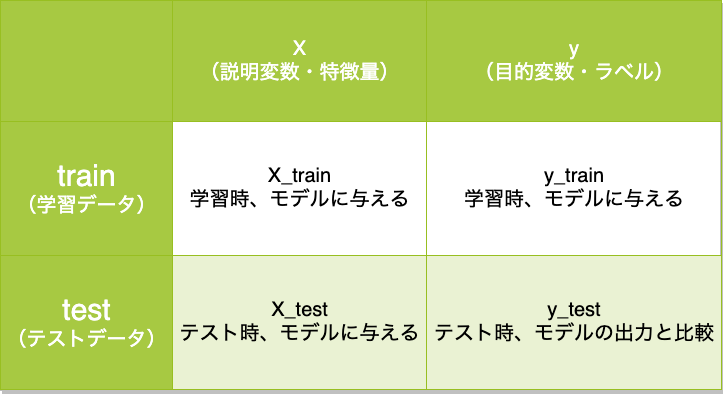
では、この機能を実装して評価を行いましょう。
実装
ということで、次回は学習データとテストデータの分割について考えます。
まずは準備です。
1 | from sklearn.datasets import load_iris |
ここまでは前回までと同様です。データをロードし、データを加工しています。
さて、ここから学習データとテストデータを分割する関数train_test_splitを実装していきます。
1 | def train_test_split(X, y, test_size=0.25, shuffle=True): |
順に解説していきます。まず引数を見ると
1 | def train_test_split(X, y, test_size=0.25, shuffle=True): |
となっておいます。
まず、引数shuffleに注目します。このオプションでshuffle=Falseを指定しない限り、データはシャッフルされた後に分割するようにします。
なぜなら、データが最初の時点で何らかの規則で並んでいる可能性があるためです。その場合、単純に分割するだけではデータに偏りが生じてしまい、正しく評価を行えません。
実際、irisもラベル単位でデータがかたまっています。
次に引数test_sizeをみましょう。これは、文字通りテストデータの比率を表しています。
つまり、test_size=0.3とした場合、
- テストデータは30%
- 学習データは残りの70%
となります。この比率については、十分に信頼できるテストデータ数となるように決めれば良いということになりますが、30%前後とすることが多いです。
次に引数X, yに着目しましょう。合わせて返り値を見ると
1 | return X_train, X_test, y_train, y_test |
となっており、Xとyを同時に分割しています。
test_sizeによって分割の比率を決めたり、shuffleによって並び替えを行うため、Xとyは個別に処理するのではなく、一度の関数呼び出しで処理する必要があります。
そのため、上記のようにX, yを受け取り、X_train, X_test, y_train, y_testを返す実装となっています。
さて、それでは学習をして評価を行ってみましょう。
実装は前回の記事とほぼ同じです。
1 | class LogisticRegression: |
おそらく100%に近い正解率が得られたでしょう。
これが正真正銘のモデルの性能といえます!
次回
これで基本的な機械学習の流れを理解できたのではないでしょうか。
実はこれまでに実装してきた
- ロジスティック回帰
- train_test_split
はscikit-learnライブラリに実装されています。
勉強のためにNumPyを用いてきましたが、実際のシーンではscikit-learnを使うことも多いでしょう。そこで、次回はこれらの内容をscikit-learnを用いて実装し直してみます。
記事情報
- 投稿日:2020年3月30日
- 最終更新日:2020年3月31日