はじめに
この記事は、連載「ゼロから始める機械学習」 の3本目の記事となります。

前回「Google Colarboratoryの使い方」 では、Google Colab環境の紹介をしました。
今回の記事でもGoogle Colab環境を用いるので準備がまだの方は、前回の記事を参考にしてください。
ローカルにJupyter環境があり、適宜読み替えられる方はJupyterでも問題ありません。
ルールベースとは
「機械学習とは?」の復習となりますが、
ある解きたいタスクに対して、
- 人間がルールを考えるのが、ルールベース
- コンピュータがルールを構築するのが、機械学習
ということになります。

そのため、機械学習を学ぶ際にいきなり機械学習の実装に入るのではなく、ルールベースのプログラムを実装すると流れが理解しやすいです。
そこで、この記事ではルールベースでタスクを解きます。
タスク
フィッシャーのアヤメと呼ばれるデータを使います。
フィッシャーのアヤメは、あるアヤメに関する「がくの長さ」「がくの幅」「花弁の長さ」「花弁の幅」といった情報から、そのアヤメが3種類のアヤメのうちどれであるかを当てるタスクです。
データの詳細はこちらを参照してください。
公式ページからデータをダウンロードしても良いのですが、scikit-learnというライブラリ経由でダウンロードができるため、今回はその手法をとります。
(scikit-learnについては連載の最後で取り扱いますが、それまでは例外的に今回を除き敢えて使わずに実装します)
実践
さて、いよいよ実装にうつりましょう。
1 | from sklearn.datasets import load_iris |
iris.dataには4種類の特徴量が、iris.targetには品種を表す番号が格納されています。
それぞれをX_org, y_orgに代入しました。
続いて、データの少し加工を加えます。
というのも条件分岐をわかりやすくするために、
- 分類する種類数を3から2に変更
- 使う特徴量を4から2に変更
します。
1 | idx = [y_org != 2] |
上記のコードの処理がわからない方は、NumPyのスライスについて復習してください。
1 | import matplotlib.pyplot as plt |
グラフ描画ライブラリをインポートしました。
1 | colors_true = ['r' if i==0 else 'b' for i in y] |
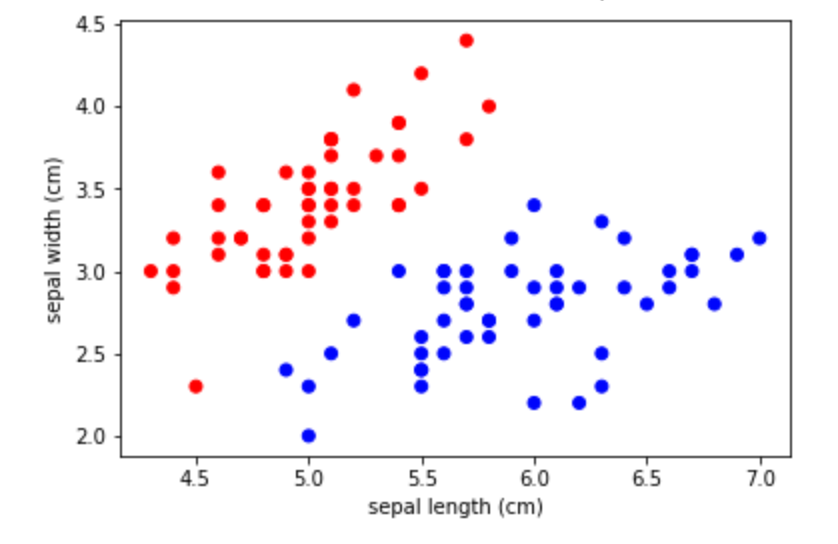
データの散布図を書いています。
品種1を赤色、品種2を青色で示しています。
plt.scatterに引数cとして、色を指定するリストを渡しています。
(rは赤、bは青を意味します)
これから、正解の品種のリストcolors_trueを使わずに、
試行錯誤しながらルールベースで同じリストを作成します。
まず、最初にcolorsを作っています。
これは、全ての要素が文字列のgのリストです。
このまま、plt.scatterでgを指定すると、緑のマーカーで描画されます。
これらを適切に赤や青に振り分けていきましょう。
先ほどのグラフを見ると
- 横軸(
sepal.length)が大きい場合は青、小さい場合は赤 - 縦軸(
sepal.width)が大きい場合は赤
と言えそうです。これを実装します。
1 | colors = ['g'] * len(y) |
うまくいったようです。
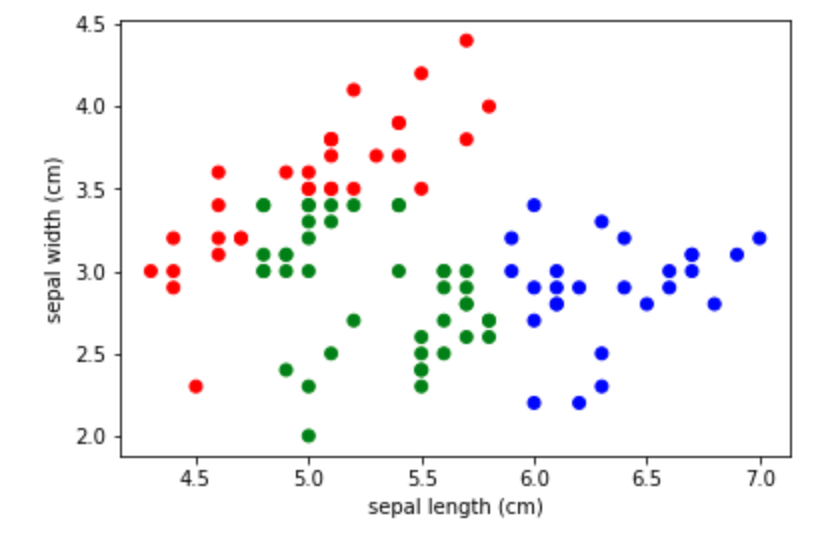
さて、残った緑の点にも対処しましょう。
これはelseを使うことで、ルールを書けますね。
1 | colors = ['g'] * len(y) |
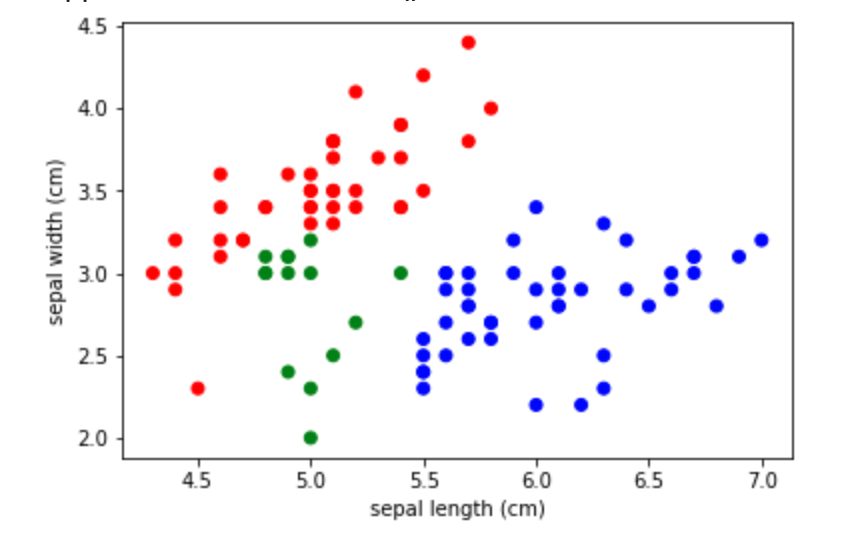
もう少しです。さらにネストを深くします。
1 | colors = ['g'] * len(y) |
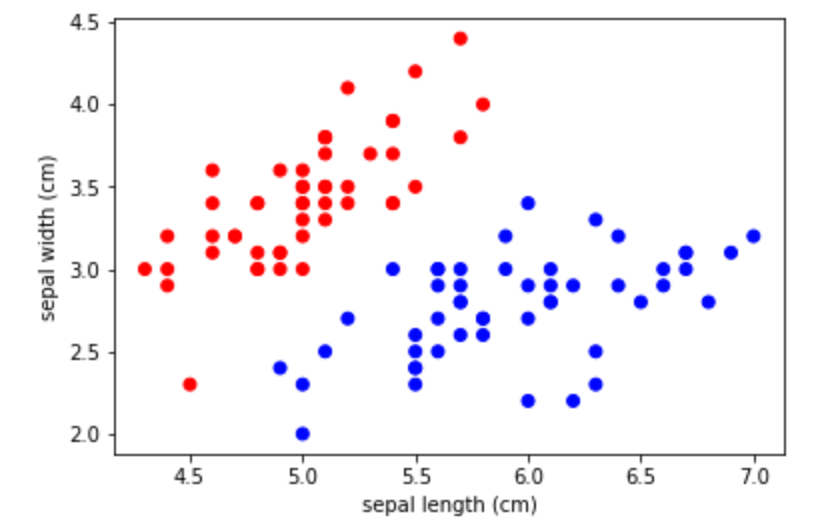
やりました。うまくいっていそうです。
1 | colors_true == colors |
Trueが返ってきました。つまり、ルールベースで完璧に分類ができました。
課題
さて、目的を達成しましたが
ここでルールベースの課題を考えましょう。
最大の問題点は、特徴量が多苦なると実装が現実的に不可能になるためです。
今回の場合、特徴量の数を2種類でした。
しかし、これが3,4と増えたらどうでしょうか。
段々とグラフが複雑になったり、グラフの枚数を増やす必要が出てきます。
3,4くらいなら、まだそれでも対応可能かもしれません。
しかし 現実のタスクでは特徴量は数万を超えることもあります。
そうなると、グラフで描画しながら人間がルールを考えていく方法には無理がありそうです。
次回
そこで、機械学習の出番となるわけです。ルールを自動でコンピュータに獲得してもらいましょう。
記事情報
- 投稿日:2020年3月28日
- 最終更新日:2020年3月29日