はじめに
連載「scikit-learnで学ぶ機械学習」を始めますに書いた通り、scikit-learnを用いて機械学習について学んで行きたいと思います。
前回の記事(第4回「検査」)では、Partial Dependence Plots(部分従属プロット)について学びました。
本記事のテーマは、「可視化」です!
機械学習モデルの評価を行う際は、数値を出すだけではなく可視化をすることで、モデルの性能について考察することができます。
ROC曲線
ROC曲線を理解するためには、True PositiveとFalse Positiveを理解する必要があります。
True PositiveとFalse Positive
二値分類を考えます。
陽性と予測し、実際に陽性であったものをTrue Positive
陽性と予測したが、実際には陰性であったものをFalse Positive
と言います。
少しややこしいですが、
一つ目の単語(TrueまたはFalse)が、実際に予測が当たったかどうか
二つ目の単語(PositiveまたはNegative)が、モデルの予測
を表します。
ROC曲線の意味
ある予測器があったとします。
予測器の感度はとても小さい、すなわち全てのサンプルを陰性と予測するとします。
この予測器の感度を徐々にあげていくと、いずれは全てのサンプルを陽性と予測するようになりますね。
その過程をプロットしたのがROC曲線です。
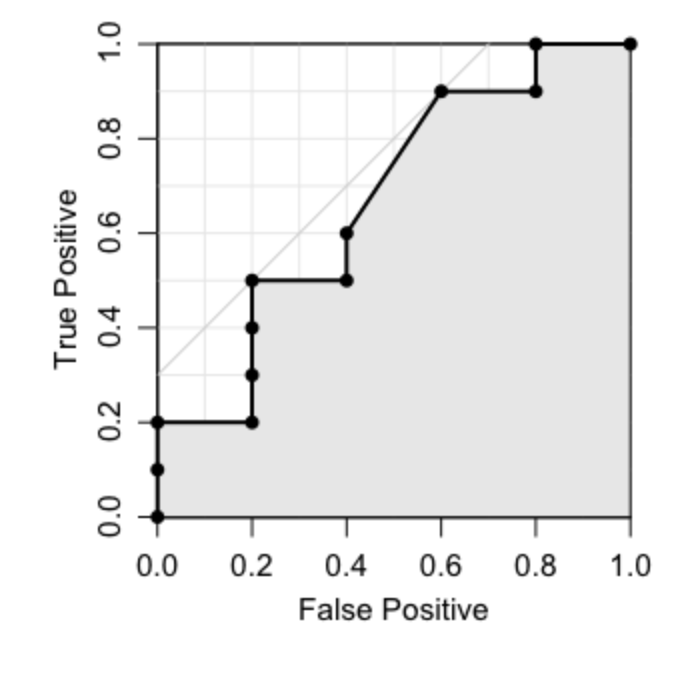
(画像は https://oku.edu.mie-u.ac.jp/~okumura/stat/ROC.html より引用)
このグラフは、
- 横軸が
False Positive Rate - 縦軸が
True Positive Rate
を表しています。
最初(感度が低く全てを陰性と予測する)は点は左下に位置していて、感度をあげると右上に移動していきます。
最後(全てを陽性と予測する)は右上に到達します。
AUC
先ほど説明したように、点は必ず最初は左下、最後は右上に位置するわけですが、
その過程を考えてみると、良い予測器ほど
False Positive Rateは小さいTrue Positive Rateは大きい
というようになるわけですから、グラフが左上を通ることになります。
このことからプロットの下部の面積でモデルの良さを測ることができます。
この面積をAUCと呼びます。
コードを動かそう
第3回「モデル選択と評価」でも利用した、breast_cancerという乳がんのデータセットを利用します。
コードの全体像
先に、完成後のソースコードを貼り付けておきます。
1 | import matplotlib.pyplot as plt |
順に解説をしていきます。
グラフ描画ライブラリのインポート
1 | import matplotlib.pyplot as plt |
乳がんデータセットのインポート
1 | from sklearn.datasets import load_breast_cancer |
train_test_splitのインポート
後ほど、学習データとテストデータの分割に用いるので、インポートします。
1 | from sklearn.model_selection import train_test_split |
モデルのインポート
この記事では、複数のモデルを比較するため3つのモデルをインポートします。
- ロジスティック回帰
- サポートベクターマシン
- 線形判別分析
1
2
3from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
ROC曲線プロットのインポート
1 | from sklearn.metrics import plot_roc_curve |
データセットのロードと分割
1 | breast_cancer = load_breast_cancer() |
タスクが簡単すぎるためモデルの差を分かりやすくするために、学習データの比率を10%としています。
モデルのインスタンスを作成
1 | lr = LogisticRegression() |
最後にリストに格納しています。
ROC曲線のプロット
1 | ax = plt.gca() |
モデルの学習をして、プロットを上書きしていきます。
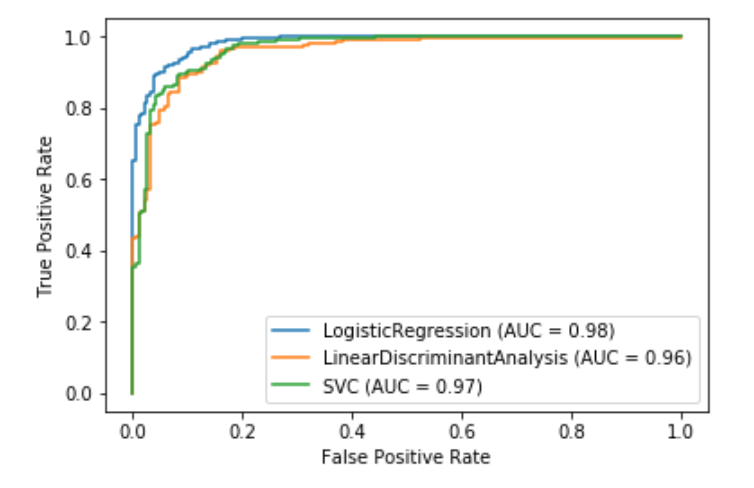
(実行環境によって結果は変わるため、これはあくまで参考です。)
AUCが最も高い(線の下部の面積が最も広い)のがロジスティック回帰(青線;AUC=0.98)であることが分かります。
すなわち、この検証においてはロジスティック回帰が最も優れているという結果となります。
まとめ
今回は、scikit-learnでのROC曲線の可視化について学びました
次回のテーマは「データセット変換」です。お楽しみに!
記事情報
- 投稿日:2020年3月6日
- 最終更新日:2020年3月22日