はじめに
連載「scikit-learnで学ぶ機械学習」を始めますに書いた通り、scikit-learnを用いて機械学習について学んで行きたいと思います。
本記事は、第3回「モデル選択と評価」です!
データを集めて学習しようと思った際に、
- どのようにモデルや学習アルゴリズムを評価するか
を決める必要があります。また
- 最適なハイパーパラメータは何か
知りたくなることもあるでしょう。そういった際に、scikit-learnのModel selection and evaluationを使うと良いです。
前々回の記事第1回「教師あり学習」や前回の記事第2回「教師なし学習」がまだの方は、そちらもどうぞ!
Model selection and evaluation
scikit-learnのModel selection and evaluationには以下のようなアルゴリズムが実装されています。
- クロスバリデーション
- グリッドサーチ
- 評価指標
今回はクロスバリデーションについて、コードを動かしながら理解してみましょう。
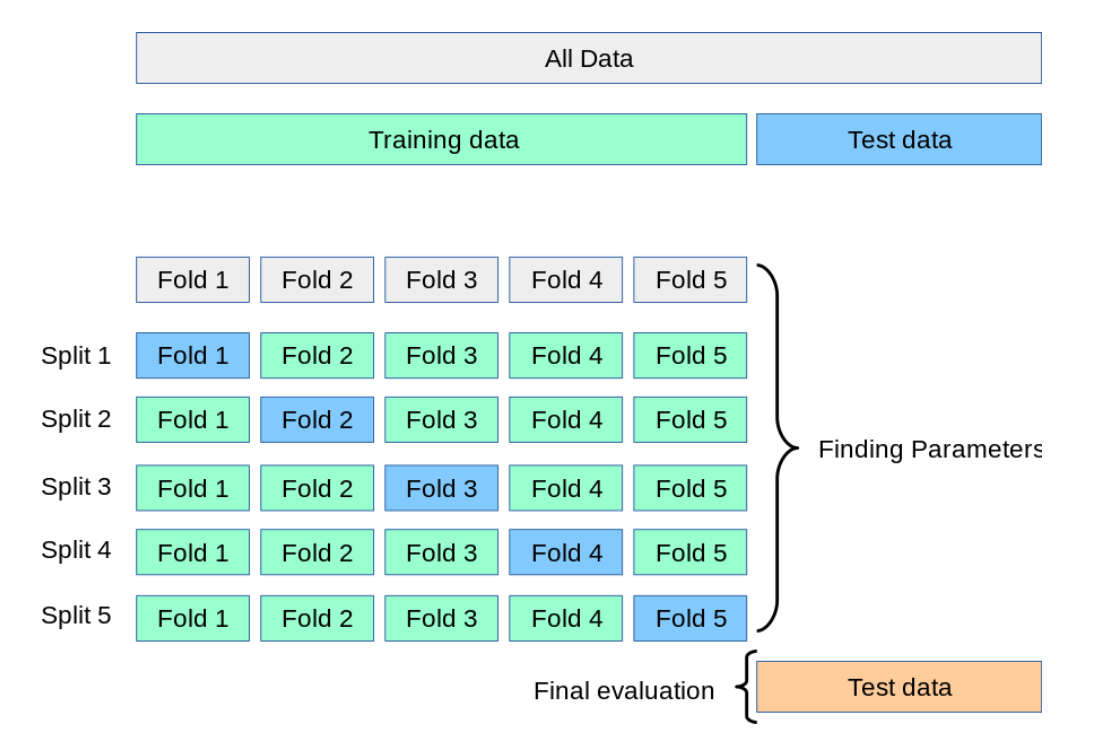
クロスバリデーションとは
第1回「教師あり学習」の記事にもきたように、学習に用いたデータを使って、評価を行うことは通常良くないとされています。
そこで、第1回「教師あり学習」では、sklearn.model_selection.train_test_splitを使って、データの70%を学習データに、30%をテストデータに利用していました。
このような方法をホールドアウト法と言います。
ホールドアウト法のデメリット
ホールドアウト法では、当然学習データとしてしか使われないデータと、テストデータとしてしか使われないデータが出てきまいます。
また、テストデータの量が全体に対して小さいため、不安定(乱数の影響を受けやすい)な指標となる場合があります。これは特に元のデータが少ない場合に顕著です。
クロスバリデーションで解決
そこでローテーションをすることで、全てのデータが学習データとしてもテストデータとしても使われるようにするのがクロスバリデーションです。
例えば、5分割する場合は学習データが80%、テストデータが20%となり、全部で5セットの学習と評価が行われることになります。
これによって、先のホールドアウト法のデメリットが解消されるわけです。ホールドアウト法の拡張として、解釈しても良いでしょう。
逆にクロスバリデーションのデメリットは計算コストが増えてしまう点ですので、その点には留意しましょう。
使い分け
基本的には、以下のようにご理解いただければOKです。
- データ量が多い時に適した手法・・・ホールドアウト法
- データ量が少ない時に適した手法・・・クロスバリデーション
コードを動かそう
第1回「教師あり学習」で扱った、ロジスティック回帰モデルでのbreast_cancerの学習をクロスバリデーションで評価してみましょう。
コードの全体像
先に、完成後のソースコードを貼り付けておきます。
1 | from sklearn.datasets import load_breast_cancer |
順に解説をしていきます。
乳がんデータセットのインポート
今回もbreast_cancerという乳がんのデータセットを利用します。
1 | from sklearn.datasets import load_breast_cancer |
cross_val_scoreのインポート
後ほど、学習データとテストデータの分割に用いるので、インポートします。
1 | from sklearn.model_selection import cross_val_score |
ロジスティック回帰モデルのインポート
1 | from sklearn.linear_model import LogisticRegression |
乳がんデータセットのロード
1 | breast_cancer = load_breast_cancer() |
Xに特徴量(説明変数、入力ベクトル)を代入
1 | X = breast_cancer.data |
全部で569サンプル、特徴量の数は30です。
yにラベル(目的変数、出力ベクトル)を代入
1 | y = breast_cancer.target |
ロジスティック回帰モデルのインスタンスを作成
1 | clf = LogisticRegression() |
このあとクロスバリデーションを行うわけですが、インスタンスの作成は通常通りでOKです。
評価を行う
1 | scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy') |
5分割のクロスバリデーションを行います。評価指標はこれまでと同じく、accuracyを用います。
5回分のスコアがリストとして返却されているのを確認しましょう。
続き
記事情報
- 投稿日:2020年3月4日
- 最終更新日:2020年3月7日