はじめに
連載「scikit-learnで学ぶ機械学習」を始めます)に書いた通り、scikit-learnを用いて機械学習について学んで行きたいと思います。
本記事は、第1回「教師あり学習」です!
- 教師あり学習の概要
- ロジスティック回帰のコード
を解説していきたいと思います
教師あり学習とは
データの構造
まず、教師あり学習で扱うデータの構造について説明します。
教師あり学習のデータは二つの要素を持っています。
それは
- 特徴量(説明変数、入力ベクトル)
- ラベル(目的変数、出力ベクトル)
です。
例えば、花の品種を予測する問題を考えてみます。
この時、
- 花弁の長さや幅・・・特徴量
- 品種・・・ラベル
となります。
教師あり学習の流れ
- 既知のデータ(特徴量とラベル)があったとします。これを学習データと呼びます。
- どのような教師あり学習のアルゴリズムを用いるか決めます。これをモデルと呼びます。
- 学習データを用いてモデルのパラメータを調整します。これを学習と呼びます。
- 未知のデータ(特徴量)とモデルを用いて未知のデータのラベルを計算します。これを予測と呼びます。
ちょっと、難しいと思われた方も大丈夫です。
コードを動かしながら理解してみましょう。
コードを動かそう
コードの全体像
先に、完成後のソースコードを貼り付けておきます。
1 | from sklearn.datasets import load_breast_cancer |
順に解説をしていきます。
乳がんデータセットのインポート
sklearn.datasetsには、様々なデータセットがあります。
今回はbreast_cancerという乳がんのデータセットを利用してみたいと思います。
細胞核の情報とその診断結果(悪性腫瘍か良性腫瘍か)がペアになっているデータセットです。
1 | from sklearn.datasets import load_breast_cancer |
train_test_splitのインポート
後ほど、学習データとテストデータの分割に用いるので、インポートします。
1 | from sklearn.model_selection import train_test_split |
ロジスティック回帰モデルのインポート
ロジスティック回帰と呼ばれる教師あり学習の中でもベーシックなモデルを使ってみたいと思います。
1 | from sklearn.linear_model import LogisticRegression |
なお、ややこしいのですがロジスティック回帰は「回帰」ではなく「分類」を行うためのモデルです。
乳がんデータセットのロード
1 | breast_cancer = load_breast_cancer() |
Xに特徴量(説明変数、入力ベクトル)を代入
1 | X = breast_cancer.data |
Xの形状を確認し、サンプル数と特徴量の数をみてみましょう。
1 | breast_cancer.data.shape |
全部で569サンプル、特徴量の数は30のようです。
次に、特徴量の名前をみてみましょう。
1 | breast_cancer.feature_names |
yにラベル(目的変数、出力ベクトル)を代入
1 | y = breast_cancer.target |
yの中身を確認してみましょう。
1 | y |
0と1でデータが表現されていることが確認できます。
余談:なぜXは大文字でyは小文字なの?
- 特徴量の形状・・・(サンプル数,特徴量の数)
- ラベルの形状・・・(サンプル数,)
となっていて、形状はそれぞれ行列とベクトルです。
そのため、scikit-learnなどのサンプルコードではその点を意識して使い分けています。
特に明確な決まりがあるわけではありませんので、スタイルの問題だと思っていただければ大丈夫です。
trainとtestに分割
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) |
sklearn.model_selection.train_test_splitを使ってデータを分割しましょう。
分割後のイメージは下の表のようになります。
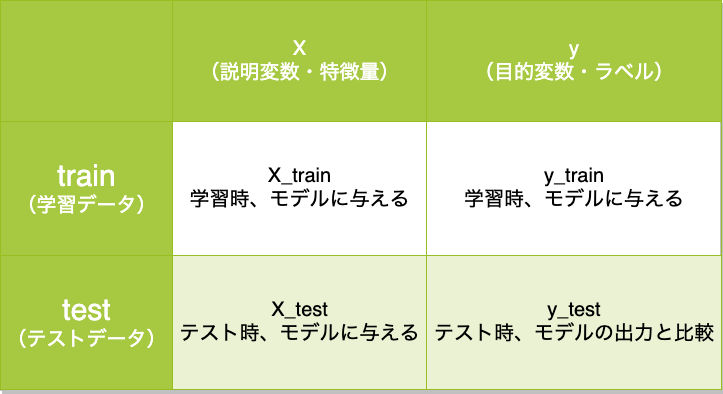
以前、こちらの記事にも書いた内容です。要約すると、
学習に用いたデータを使って、評価を行うことは通常良くないとされています。
私たち人間が受けるテストと同じで、
「事前にテストの問題が公表されているテスト」は暗記してしまえば良いのであまり意味がないです。
「事前にテストの類題や過去問は公表するが、本番のテストの内容は公表しないテスト」
方が適切に評価ができるというわけです。
ロジスティック回帰モデルのインスタンスを作成
1 | clf = LogisticRegression() |
モデルの学習を行う
1 | clf.fit(X_train, y_train) |
テストデータで評価を行う
予測と正解が一致しているかを全てのテストサンプルについて確認し、平均をとります。
これが、scoreメソッドで一発でできます。
1 | print (clf.score(X_test, y_test)) |
scoreメソッドを使わずに書き下すと、以下のようになります。
1 | print ((clf.predict(X_test)==y_test).mean()) |
続き
記事情報
- 投稿日:2020年3月2日
- 最終更新日:2020年3月7日