はじめに
連載「scikit-learnで学ぶ機械学習」を始めますに書いた通り、scikit-learnを用いて機械学習について学んで行きたいと思います。
本記事は、第4回「検査」です!
近年、機械学習では解釈性のニーズが高まっています。
機械学習において解釈性とは、
なぜモデルがその予測をしたかを説明できるかどうか
ということです。
この記事ではsklearnを使って、
どの特徴量が予測に影響しているかを可視化してみたいと思います。
Partial dependence plots
Partial Dependence Plots(部分従属プロット)は、
学習済みのモデルに対して、どの特徴量が予測に影響しているかをプロットします。
先に、このアルゴリズムでプロットした図をみてみましょう。
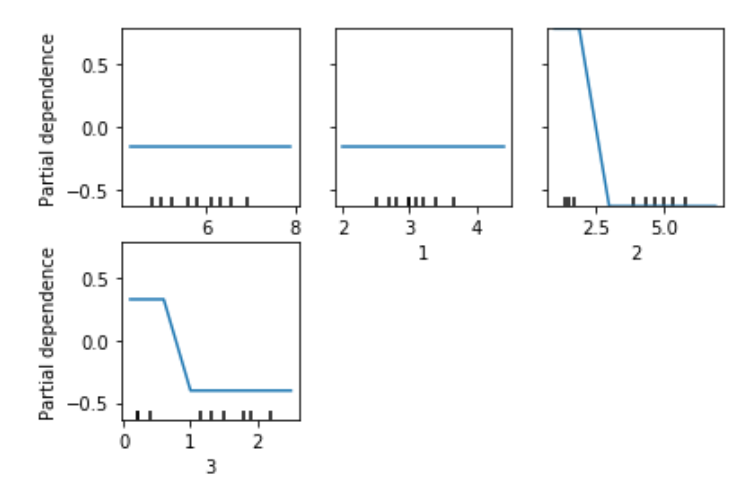
4つの図があると思います。
各図の横軸が説明変数(特徴量)、縦軸が目的変数(ラベル)に対応しています。
左上・左中央の図は水平なグラフとなっていますが、
右上・左下の図は傾いている箇所があることがわかります。
グラフが傾いている場合、それらの特徴量が予測に影響している
という意味を持ちます。
コードを動かそう
機械学習のコードを動かしてみよう(scikit-learn)でも利用した、フィッシャーのアヤメと呼ばれるデータを利用してみたいと思います。
コードの全体像
先に、完成後のソースコードを貼り付けておきます。
1 | from sklearn.datasets import load_iris |
順に解説をしていきます。
アヤメデータセットのインポート
1 | from sklearn.datasets import load_iris |
ロジスティック回帰モデルのインポート
1 | from sklearn.linear_model import LogisticRegression |
部分従属プロットのインポート
1 | from sklearn.inspection import plot_partial_dependence |
グラフ描画ライブラリのインポート
1 | import matplotlib.pyplot as plt |
as pltとするのが通例です。
アヤメデータのロード
1 | iris = load_iris() |
先ほど説明したアヤメのデータを変数irisに代入する。
Xに特徴量(説明変数、入力ベクトル)を代入
1 | X = iris.data |
1 | X.shape |
データの数(サンプル数)が150で説明変数の種類(次元)が4であることが確認できます。
yにラベル(目的変数、出力ベクトル)を代入
1 | y = iris.target |
今回のtargetは0,1,2のいずれかの数字が保持されています。
つまり、3クラス分類問題です。
ロジスティック回帰モデルのインスタンスを作成
1 | clf = LogisticRegression() |
多クラス分類問題でも、2クラス分類問題と同様の書き方でインスタンスを作成します。
学習を行う
1 | clf.fit(X, y) |
今回は正解率の評価は行わないので、データを分割しません。
プロットの準備
1 | features = range(0,4) |
プロットに利用するリストを作成します。
4は特徴量の数です。
部分従属プロット
1 | plot_partial_dependence(clf, X, features, target=0) |
コードを実行すると上の図のようにグラフが表示されると思います。
(グラフの形は異なる場合があります)
target=0の意味ですが、これはラベル0のクラスの予測に対しての
各特徴量の影響を出力せよ、という意味です。他のクラスについてもみていきましょう。
部分従属プロット(続き)
1 | plot_partial_dependence(clf, X, features, target=1) |
まとめ
今回は、scikit-learnでの検査(部分従属プロット)について学びました。
次回のテーマは「可視化」です。お楽しみに!
第5回「可視化」
記事情報
- 投稿日:2020年3月4日
- 最終更新日:2020年3月22日