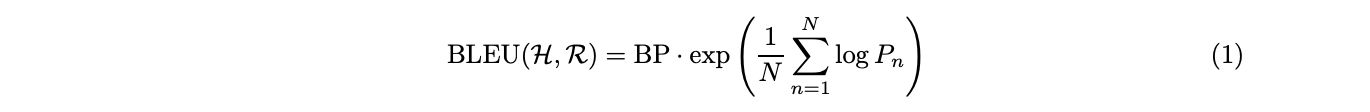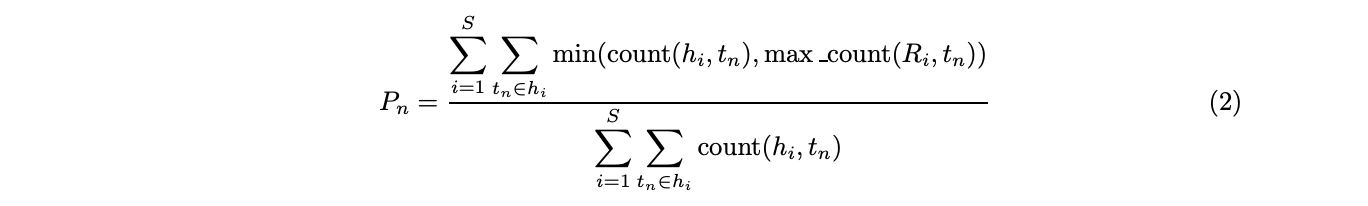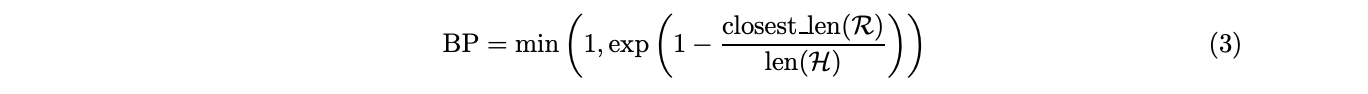import itertools N, K = map(int,input().split()) A = list(map(int,input().split())) K = min(41,K) for k in range(K): imos = [0] * (N+1) for n in range(N): a = n - A[n] b = n + A[n] a = max(0,a) b = min(N-1,b) imos[a] += 1 imos[b+1] -= 1 csum = list(itertools.accumulate(imos)) A = csum[:-1] A = [str(a) for a in A] print (' '.join(A))
defmain(): ans = [] N = 10**6 dp = [10**10]*(N+1) dp_odd = [10**10]*(N+1) dp[0] = 0 dp_odd[0] = 0
for i in range(1,10**3): w = i*(i+1)*(i+2)//6 if N<=w: break for n in range(N-w): # dp[n+w] = min(dp[n]+1,dp[n+w]) # TLE new = dp[n] + 1 if new < dp[n+w]: dp[n+w] = new if w&1==1: for n in range(N-w): #dp_odd[n+w] = min(dp_odd[n]+1,dp_odd[n+w]) # TLE new = dp_odd[n] + 1 if new < dp_odd[n+w]: dp_odd[n+w] = new while(1): S = int(input()) if S==0:break ans.append([dp[S],dp_odd[S]]) for a,b in ans: print(a,b) if __name__ == '__main__': main()
N = int(input()) S = [] col = {'R':0, 'B':1, 'W':2, '#':-1} for i in range(5): s = input() ls = list(s) ls = [-1] + [col[e] for e in ls] # 最も左の列にダミーを入れて奥 S.append(ls) dp = [[0]*3for _ in range(N+1)]
for n in range(N): for i in range(3): cnt = 0 for j in range(5): cnt += (S[j][n+1] != i) K = [0,1,2] K.remove(i) # 同じ色は隣合えない dp[n+1][i] = min(dp[n][K[0]] + cnt, dp[n][K[1]] + cnt) print (min(dp[-1]))
N, M = map(int, input().split()) D = [] C = [] for n in range(N): d = int(input()) D.append(d) for m in range(M): c = int(input()) C.append(c)
dp = [[10**10]*(M+1) for _ in range(N+1)] for m in range(M+1): dp[0][m] = 0 for n in range(N): for m in range(M): dp[n+1][m+1] = min(dp[n+1][m], dp[n][m]+D[n]*C[m]) print (dp[-1][-1])
D, N = map(int,input().split()) T = [] for d in range(D): T.append(int(input())) A = [] B = [] C = []
for n in range(N): a,b,c = map(int,input().split()) A.append(a) B.append(b) C.append(c)
dp = [[-10**8]*N for _ in range(D+1)] # 最大値を求める問題で、初日のスコアが0になるので-infで初期化
for d in range(D): t = T[d] for n in range(N): if A[n] <= t <= B[n]: if d==0: dp[d+1][n] = 0# 初日はスコアが加算されない continue for m in range(N): dp[d+1][n] = max(dp[d][m] + abs(C[n]-C[m]),dp[d+1][n]) print (max(dp[-1]))
MOD = 10**4 N, K = map(int, input().split()) A = [0] * N for k in range(K): a, b = map(int, input().split()) A[a-1] = b dp = [[[0]*4for i in range(4)] for j in range(N+1)] dp[0][0][0] = 1 for n in range(N): for i in range(4): for j in range(4): for k in range(1,4): if A[n]!=0and A[n]!=k: # パスタが指定されているのにkが違えばスキップ continue if k != i or i != j: # 三日連続ではない場合 dp[n+1][k][i] += dp[n][i][j] dp[n+1][k][i] %= MOD
ans = 0 for i in range(4): # 最終日、全ての状態の分を足す for j in range(4): ans += dp[-1][i][j] ans %= MOD
N = int(input()) A = list(map(int, input().split())) M = 20 dp = [[0]*(M+1) for _ in range(N-1)] dp[0][A[0]] = 1 A = A[1:] for n in range(N-2): for m in range(M+1): if m-A[n] >= 0: dp[n+1][m] += dp[n][m-A[n]] if m+A[n] <= M: dp[n+1][m] += dp[n][m+A[n]] print (dp[-1][A[-1]])
defsolve(W,H,ver,hor): dist = [ [0]*W for _ in range(H)] dist[0][0] = 1 q = deque() q.append((0,0)) # スタート地点をenqueue while(q): y, x = q.popleft() if y==H-1and x==W-1: break else: for dx, dy in dxdy: if (dx==-1and ver[y][x]==0) or (dx==1and ver[y][x+1] == 0) or (dy==-1and hor[y][x]==0) or (dy==1and hor[y+1][x]==0): # 通行可能か if dist[y+dy][x+dx] == 0: # 未訪問か q.append((y+dy,x+dx)) dist[y+dy][x+dx] = dist[y][x] + 1# 距離を記録 return dist[H-1][W-1] ans = [] while(1): W, H = map(int,input().split()) if W==0and H==0: break ver = [] # 垂直方向の壁 hor = [] # 水平方向の壁 hor.append([1]*W) # 一番上の壁(スタート地点から始めるので、入口を塞いで問題ない) for i in range(2*H-1): bar = list(map(int,input().split())) if i%2==0: ver.append([1]+bar+[1]) # 一番左と右にも壁を設置 else: hor.append(bar) hor.append([1]*(W+1)) # 一番下の壁(ゴール地点につけば終了するので、出口を塞いで問題ない) ans.append(solve(W,H,ver,hor))
import unittest import numpy as np import nltk import math from collections import Counter
defbleu_score(reference, hypothesis, weights=[1/4]*4): if len(hypothesis) == 0: return0 N = min(4,len(hypothesis)) ref_lens = (len(ref) for ref in reference) closest = min( ref_lens, key=lambda ref_len: (abs(ref_len - len(hypothesis)), ref_len) ) bp = min(1, math.exp(1-closest/len(hypothesis)))
sm = 0 for i in range(1,N+1): lh = [] for k in range(len(hypothesis)-i+1): lh.append(' '.join(hypothesis[k:k+i])) ch = Counter(lh) s = 0 for t in ch: mn = 0 max_count = 0 for ref in reference: lr = [] for k in range(len(ref)-i+1): lr.append(' '.join(ref[k:k+i])) cr = Counter(lr) max_count = max(max_count, cr[t]) mn = min(ch[t], max_count) s += mn / len(lh) if s==0: if i==1: return0 else: pass else: sm += weights[i-1] * math.log(s) return bp*math.exp(sm)