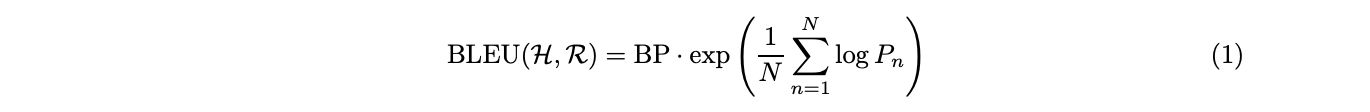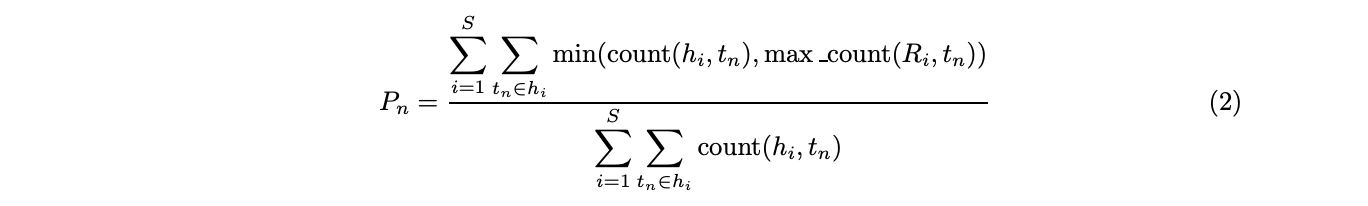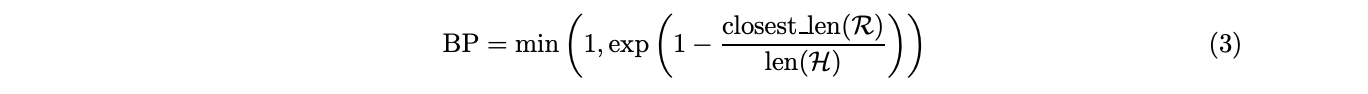BLEUスコアとは BLEUスコアは機械翻訳の結果を評価するための指標です。値は0~1の間の実数です。
参考 によると、目安は下記のようになります。
1 2 3 4 5 6 7 0.1以下 ほとんど役に立たない 0.1~0.2 主旨を理解するのが困難である 0.2~0.3 主旨は明白であるが、文法上の重大なエラーがある 0.3~0.4 理解できる、適度な品質の翻訳 0.4~0.5 高品質な翻訳 0.5~0.6 非常に高品質で、適切かつ流暢な翻訳 0.6以上 人が翻訳した場合よりも高品質であることが多い
以下のように定義されます。
ただし、
1 2 3 4 5 H: システム翻訳文集合 R: 参照翻訳文集合 N: N-gramの長さ(4が用いられる場合が多い) tn: 任意のN-gramトークン closest_len(R): システム翻訳文の長さに最も近い参照翻訳文の長さ
を表します。
語順の相関に基づく機械翻訳の自動評価法 から引用させていただきました。
NLTK BLEUスコアはnltkに実装されています。システム翻訳文集合の要素数が1の場合、nltk.translate.bleu_score.sentence_bleuを利用します。
1 2 import nltknltk.translate.bleu_score.sentence_bleu(references, hypothesis)
システム翻訳文集合の要素数が複数ある場合、nltk.translate.bleu_score.corpusを利用します。
1 nltk.translate.bleu_score.corpus_bleu(list_of_references, hypotheses)
スクラッチで実装 今回はこれをスクラッチで実装します。テストのために、nltk.translate.bleu_score.sentence_bleuを用います。
システム翻訳文集合(hypothesis)は一つのシステム翻訳文のみを含むとして実装します。一つのシステム翻訳文に対して参照翻訳文の集合(references)が対応します。
Brevity Penalty 適合率Pnは、翻訳文の長さが短いほど高くなる傾向があります。BLEUスコアでは、それを補正するためにBP(Bravity Penalty)を導入します。参照翻訳文に対して、システム翻訳文の長さが短い場合にペナルティを与えます。
ハマったポイント NLTKではclosest_lenを以下のように実装しています。例えば、システム翻訳文の長さが5の場合、参照翻訳文の長さが4でも6絶対値は1となりますが、絶対値が最小の長さを与えるのは長さが小さい方、すなわち4の時となるように実装しているようです。
1 2 3 4 ref_lens = (len(reference) for reference in references) closest_ref_len = min( ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len) )
そのためfor文を用いて最小値を更新する実装をした場合、結果が一致しない場合があるので注意が必要です。
N-gram スライスを利用することでN-gramを実装します。
1 2 3 4 5 for i in range(1 ,N+1 ):lh = [] for k in range(len(hypothesis)-i+1 ): lh.append(' ' .join(hypothesis[k:k+i])) ch = Counter(lh)
count 標準ライブラリのcollections.Counterを用いると良いです。
1 from collections import Counter
コード全体 テストコードも含めた全コードです。NLTKのバージョン3.2.5でテストが通ることを確認しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import unittestimport numpy as npimport nltkimport mathfrom collections import Counterdef bleu_score (reference, hypothesis, weights=[1 /4 ]*4 ) : if len(hypothesis) == 0 : return 0 N = min(4 ,len(hypothesis)) ref_lens = (len(ref) for ref in reference) closest = min( ref_lens, key=lambda ref_len: (abs(ref_len - len(hypothesis)), ref_len) ) bp = min(1 , math.exp(1 -closest/len(hypothesis))) sm = 0 for i in range(1 ,N+1 ): lh = [] for k in range(len(hypothesis)-i+1 ): lh.append(' ' .join(hypothesis[k:k+i])) ch = Counter(lh) s = 0 for t in ch: mn = 0 max_count = 0 for ref in reference: lr = [] for k in range(len(ref)-i+1 ): lr.append(' ' .join(ref[k:k+i])) cr = Counter(lr) max_count = max(max_count, cr[t]) mn = min(ch[t], max_count) s += mn / len(lh) if s==0 : if i==1 : return 0 else : pass else : sm += weights[i-1 ] * math.log(s) return bp*math.exp(sm) class TestBleu (unittest.TestCase) : def setUp (self) : np.random.seed(0 ) def test_hand_craft_case (self) : nltk_score = nltk.translate.bleu_score.sentence_bleu(reference, hypothesis) my_score = bleu_score(reference, hypothesis) print (nltk_score, my_score) self.assertAlmostEqual(nltk_score, my_score) def test_random_case (self) : for i in range(1000 ): vocab = np.array(['a' ,'b' ,'c' ,'d' ,'e' ]) n_word = np.random.randint(10 ) n_ref = np.random.randint(1 ,5 ) idx = np.random.choice(len(vocab), n_word) hypothesis = vocab[idx].tolist() reference = [] for j in range(n_ref): n_word = np.random.randint(10 ) idx = np.random.choice(len(vocab), n_word) ref = vocab[idx].tolist() reference.append(ref) nltk_score = nltk.translate.bleu_score.sentence_bleu(reference, hypothesis) my_score = bleu_score(reference, hypothesis) self.assertAlmostEqual(nltk_score, my_score) if __name__ == '__main__' : unittest.main()
記事情報
投稿日:2020年6月6日
最終更新日:2020年6月6日