はじめに
機械学習の題材を探してみると画像処理・言語処理は多く見つかるものの、音声処理はあまり多くありません。ビジネスのニーズとしては(比較的)小さいからでしょうか。今回はKaggleのコンペティションFree Sound Audio Tagging 2019を使って、音声処理について紹介します。
Free Sound Audio Tagging 2019
https://www.kaggle.com/c/freesound-audio-tagging-2019
音声をマルチラベル分類するタスクです。ラベルは例えば
- Bark
- Raindrop
- Finger_snapping
- Run
などがあります。
音声処理に馴染みがない方は、このタスクをどう解いていけば良いかなかなか思い浮かばないかもしれません。
そういう時は優勝者のソリューションに学びましょう。
優勝者のソリューション
https://www.kaggle.com/c/freesound-audio-tagging-2019/discussion/95924
- 特徴量: ログスケールのメルスペクトログラム
メルスペクトログラムは音声処理特有の特徴量です。 - モデル: CNN(注意機構、スキップコネクション、auxiliary classifiers)
モデルについてはCNNを利用しており、機械学習に触れたことがある方なら特に問題ないでしょう。 - データ拡張: SpecAugment, Mixup
SpecAugmentは音声処理特有のデータ拡張手法です。 - アンサンブル
Kaggleではスコアの底上げのためにアンサンブルがよく用いられ、特に音声処理に限った話ではないです。
細かな違いはありますが、他の上位入賞者のソリューションも似ています。
特徴量: ログスケールのメルスペクトログラム
特徴量を作成する前に実際に音声を聞いてみましょう。Jupyterでは音声を聞くこともできます。
なお、本記事のコードは全てGitHubにアップロードしています。
1 | import IPython.display as ipd |
メルスペクトログラムの計算のためにlibrosaを用います。librosaは音声解析用途のPythonライブラリです。
https://github.com/librosa/librosa
librosaで音声ファイルをロードします。
1 | import librosa |
yは音声の時系列信号、srはサンプリングレートを表します。
これをそのまま受け取り、メルスペクトログラムを計算する関数が用意されています。librosa.feature.melspectrogramで何をしているのかの詳細についてはlibrosa.feature.melspectrogramのコードを読むに書きました。
1 | melspec = librosa.feature.melspectrogram(y, sr) |
可視化してみましょう。
1 | import librosa.display |

なんだか暗くてよくわかりません。ログスケールに変換します。
1 | log_melspec = librosa.power_to_db(melspec) |
1 | librosa.display.specshow(log_melspec) |
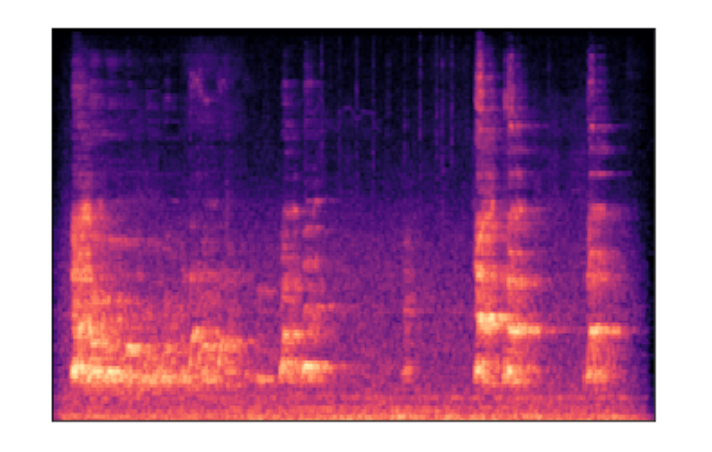
今度は特徴がはっきり取れました。これならCNNの入力として使えそうですね。
データ拡張手法
追記予定
記事情報
- 投稿日:2020年6月29日
- 最終更新日:2020年7月1日