概要
この記事では、csvデータをpandasで読み込み、scikit-learnで学習させる方法について解説します。
では、sklearn.datasetsのデータを使ってscikit-learnの学習方法について学びました。
しかし、実際に機械学習を行うと思った場合、csvデータを利用する必要もあるはずです。
この記事では、csv形式で与えられるフィッシャーのアヤメデータを学習します。
データのダウンロード
まず、作業ディレクトリを作成してください。
こちらのリンクから、iris.dataをダウンロードしてください。拡張子は.dataとなっていますが、中身はcsvフォーマットで書かれています。
ダウンロードしたデータを作業ディレクトリに配置してください。
準備はこれで完了です。
コード
先ずは、今回動かすコードを見てみましょう。このコードを1行ずつ紹介していきます。
1 | import pandas as pd |
pandasのインポート
1 | import pandas as pd |
pandasはデータ分析用のライブラリで、表形式のデータを扱うことができます。
train_test_splitのインポート
後ほど、学習データとテストデータの分割に用いるので、インポートします。
1 | from sklearn.model_selection import train_test_split |
ニューラルネットワークのインポート
1 | from sklearn.neural_network import MLPClassifier |
今回はモデルとしてニューラルネットワークを用います。
csvをロードする
1 | df = pd.read_csv('./iris.data', header = None) |
pandasではread_csv関数を用いて、csvをロードすることができます。
第一引数にcsvファイルまでのパスを記します。
iris.dataにはヘッダーがないため、header=Noneを指定しています。
ヘッダーを含むデータの場合は、指定する必要がありません。
データの確認をする
では、データをどのような形式となっているのでしょう。
1 | type(df) |
pandasのDataFrameと呼ばれる二次元の表形式のデータとなっています。
あなたが、ノートブックや対話モードでスクリプトを実行している場合、以下のコマンドを実行することで、テーブルの先頭を確認することができます。
1 | head() |
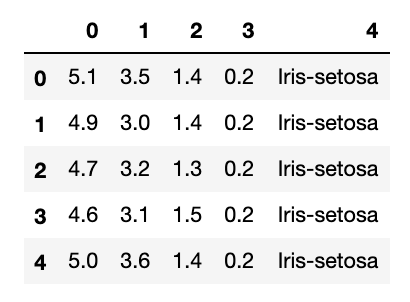
numpy.ndarrayへの変換
scikit-learnではpandasのDataFrameを直接扱うことができません。
そこで、まずpandas.Dataframeをnumpy.ndarrayに変換します。
これはvalues()メソッドで行うことができます。
1 | arr = df.values |
データの型を確認しましょう。
1 | type(arr) |
特徴量とラベルの定義
フィッシャーのアヤメのデータは、アヤメの「がくの長さ」「がくの幅」「花弁の長さ」「花弁の幅」からアヤメの種類を分類するためのデータです。
データを見るとわかりますが、
- ラベル・・・最後の一列
- 特徴量・・・それ以外
となっていることがわかります。
そこでスライスを行い、特徴量(X)とラベル(y)を作成します。
1 | X = arr[:,:-1] |
学習データとテストデータの分割
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) |
train_test_splitを使ってデータを学習用データとテストデータに分割しています。それぞれに目的変数と説明変数があるため、返却されるオブジェクトは4つとなります。test_sizeは分割の比率を決めるパラメータで、ここでは30%をテストデータに、残りの70%を学習用データとしています。
ニューラルネットワークのインスタンスを作成
1 | clf = MLPClassifier() |
学習
1 | clf.fit(X_train, y_train) |
予測およびスコアの計算
1 | print (clf.score(X_test, y_test)) |
おわりに
MENTAというサービスでプログラミング学習のサポートをしています。競技プログラミングについてもサポートできるので、ご興味がある方はぜひMENTAのDMでご連絡いただければと思います。
記事情報
- 投稿日:2020年3月21日
- 最終更新日:2022年1月8日