はじめに
連載「scikit-learnで学ぶ機械学習」を始めますに書いた通り、scikit-learnを用いて機械学習について学んで行きたいと思います。
前回の記事第6回「データセット変換」では、標準化について学びました。
本記事のテーマは、「データセット読み込みユーティリティ」です!
scikit-learnでは、標準で利用できるデータセットが準備されています。
これらのデータセットはサンプルコードなどでよく使われます。
実際これまでの記事でもirisやbreast_cancerを利用させていただきました。
今回はそんな「データセット読み込みユーティリティ」の使い方を紹介していきます。
データの種類
scikit-learnでは、データは大きく以下の二つに分類されています。
- Toy Datasets
- Real World Datasets
前者の場合、ライブラリの中にデータセットが含まれているのでオフラインでも動作します。
後者の場合、初めて利用する際にはデータをweb経由でロードするため時間がかかります。
Toy Datasets
- boston
- iris
- diabetes
- digits
- linnerud
- wine
- breast_cancer
Real World Datasets
- olivetti_faces
- 20newsgroups
- 20newsgroups_vectorized
- lfw_people
- lfw_pairs
- covtype
- rcv1
- kddcup99
- california_housing
コードを動かそう
今回はToy Datasetsのdigitsを利用しようと思います。
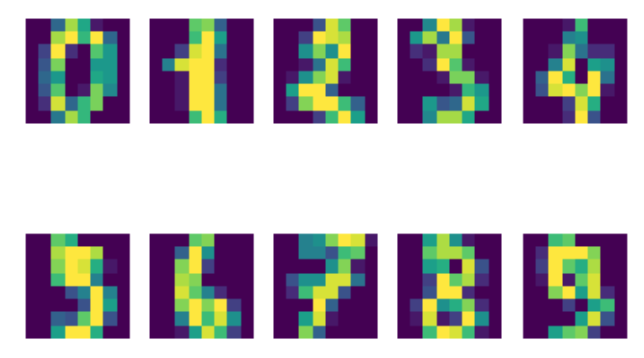
digitsデータセットの概要
0~9までのグレースケールの数字の画像です。
画素数は8×8ピクセルで、1797枚の
コードの全体像
先に、完成後のソースコードを貼り付けておきます。
1 | from sklearn.datasets import load_digits |
データセットローダーのインポート
1 | from sklearn.datasets import load_digits |
digitsのデータセットローダーをインポートします。
グラフ描画ライブラリのインポート
1 | import matplotlib.pyplot as plt |
データセットのロード
下記のようにするだけで必要なデータを全てdigitsに展開できます。
1 | digits = load_digits() |
データの確認
ここで、データの確認をしてみましょう。
1 | dir(digits) |
順に
- DESCR・・・データセットの概要
- data・・・特徴量
- images・・・特徴量を二次元配列(8×8)に変形したもの
- target・・・ラベル
- target_names・・・ラベル名
となっています。
特徴量、ラベルの形状の確認
1 | print (digits.data.shape) |
画像の確認
1 | for i,img in enumerate(digits.images[:10]): |
以下のように描画されれば成功です。
まとめ
scikit-learnのデータセットローダーの使い方がご理解いただけたでしょうか。
次回のテーマは第8回「scikit-learnによる計算」で、増分学習にいて扱います。お楽しみに!
記事情報
- 投稿日:2020年3月8日
- 最終更新日:2020年3月9日