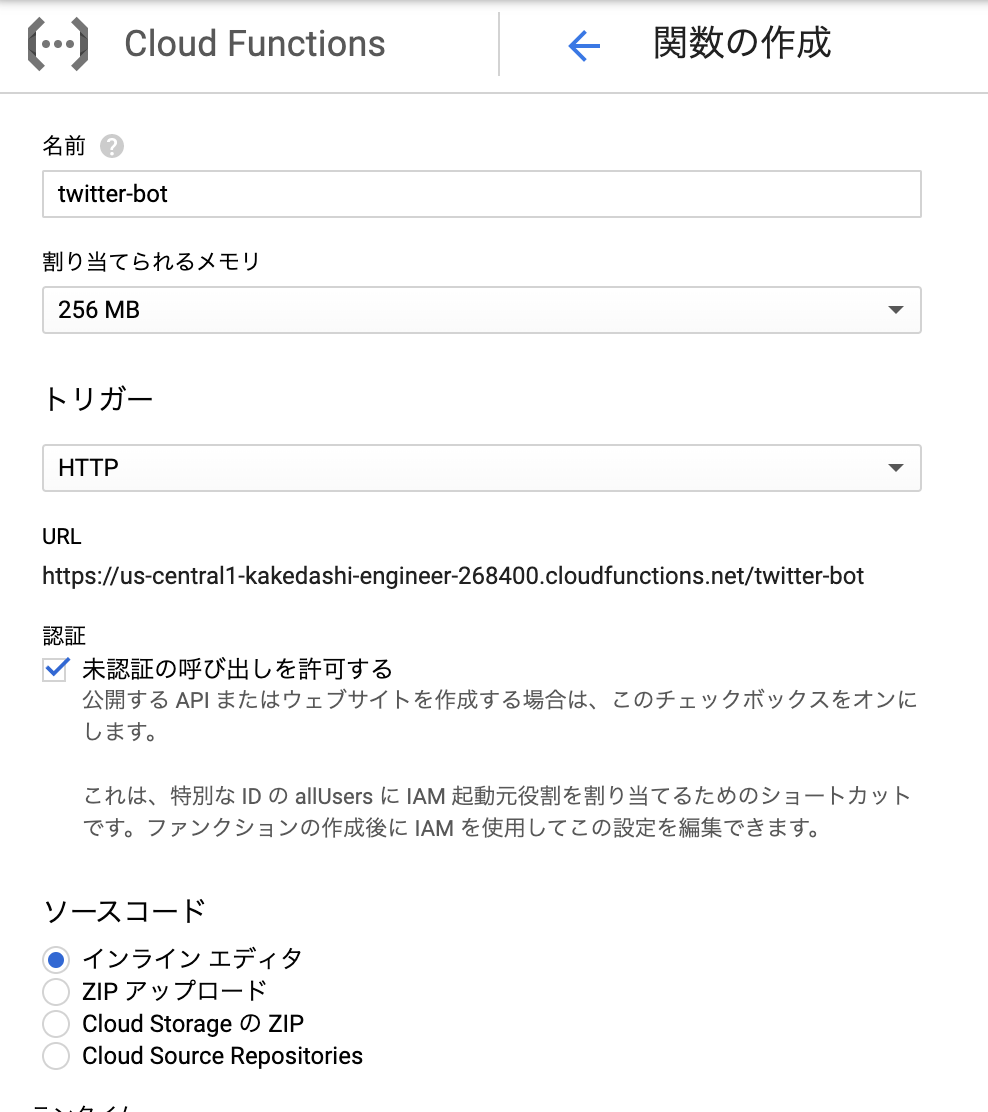
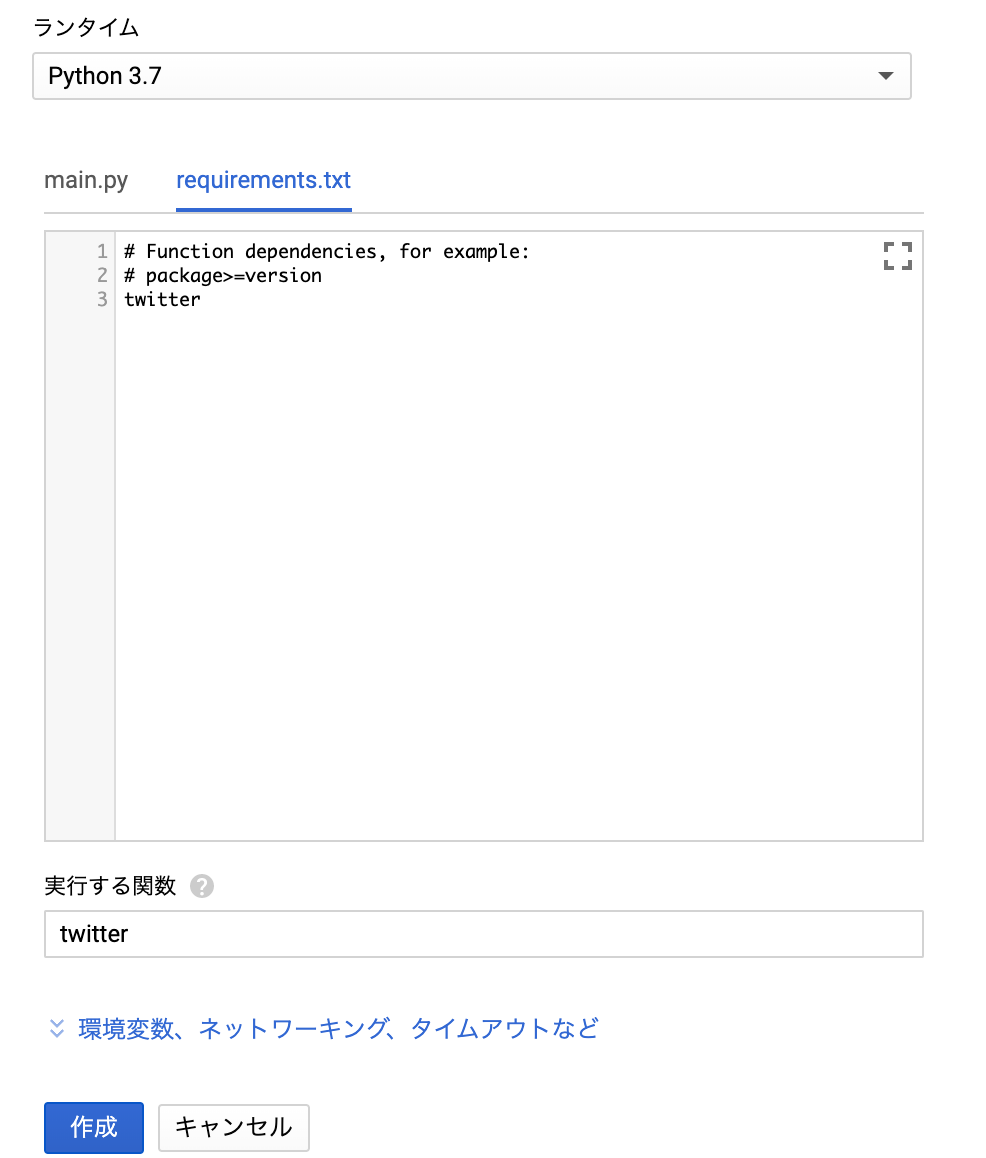
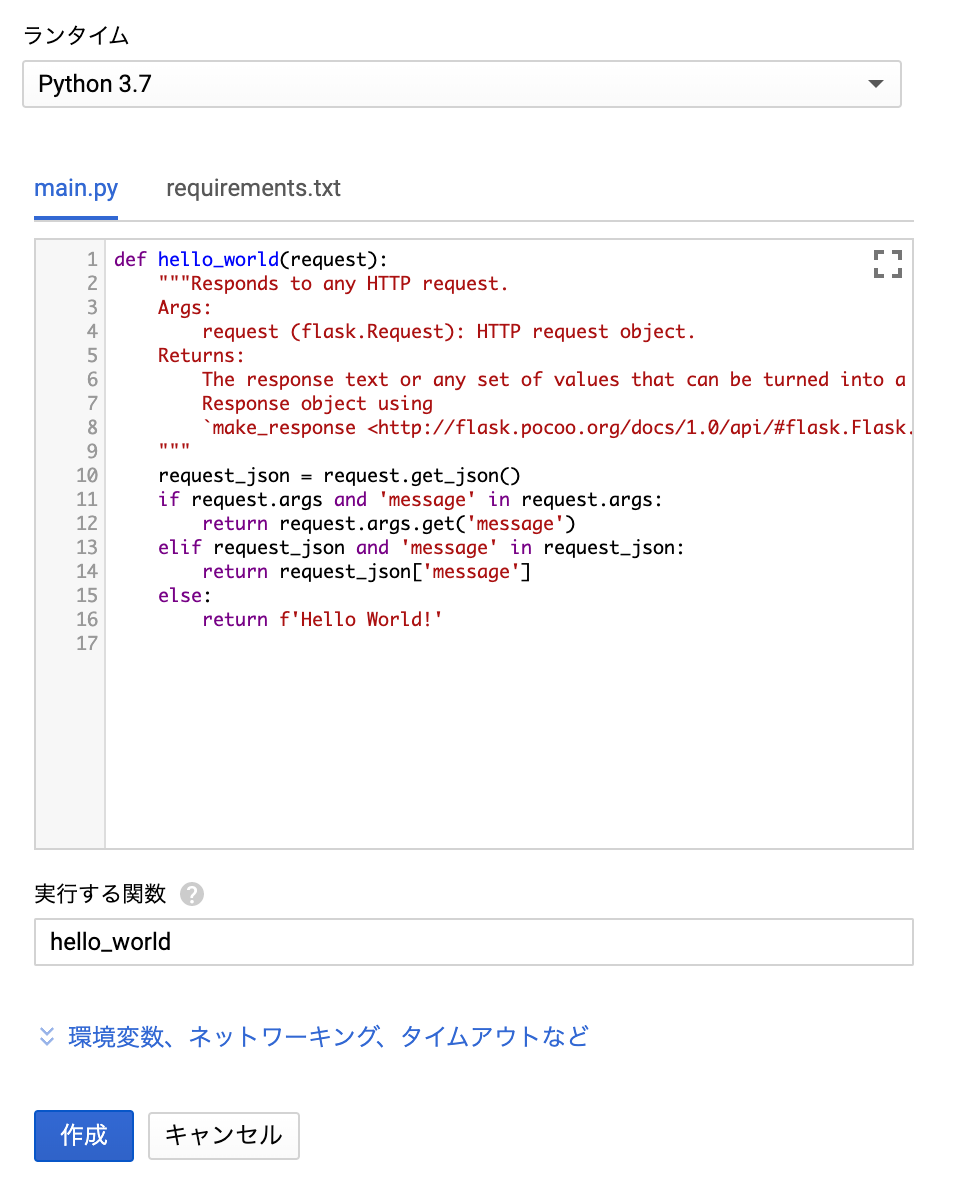
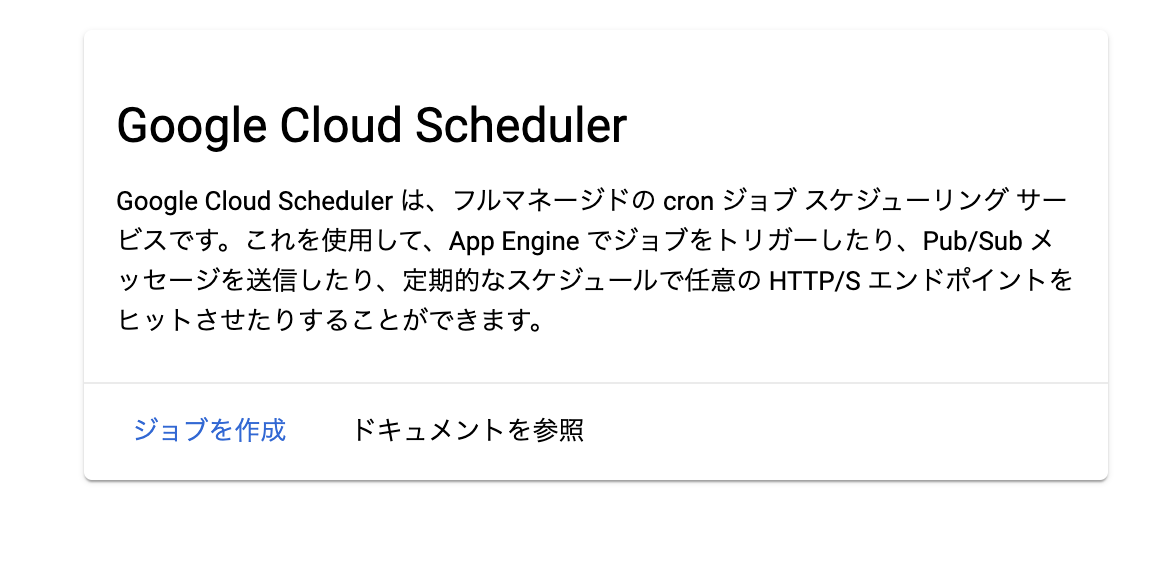
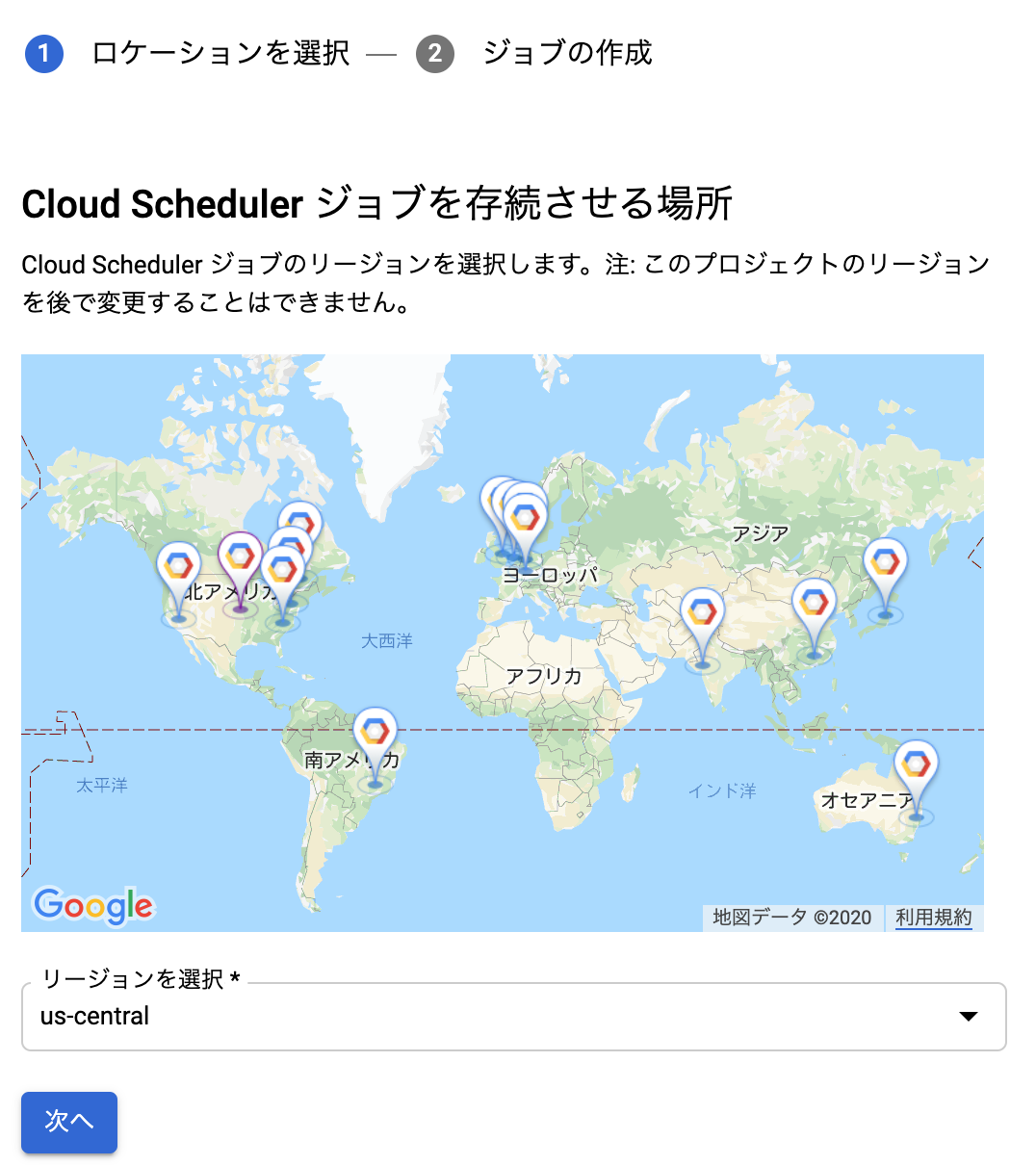
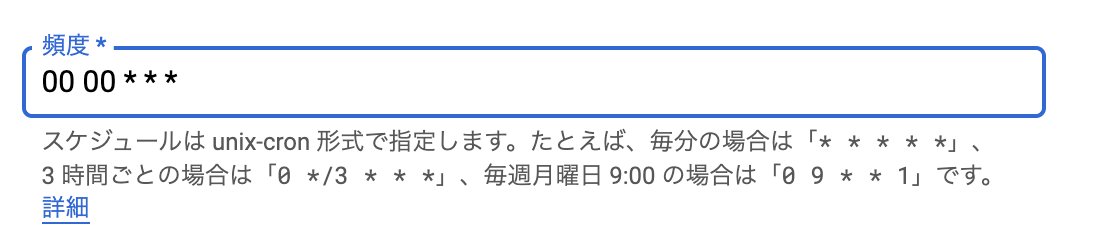
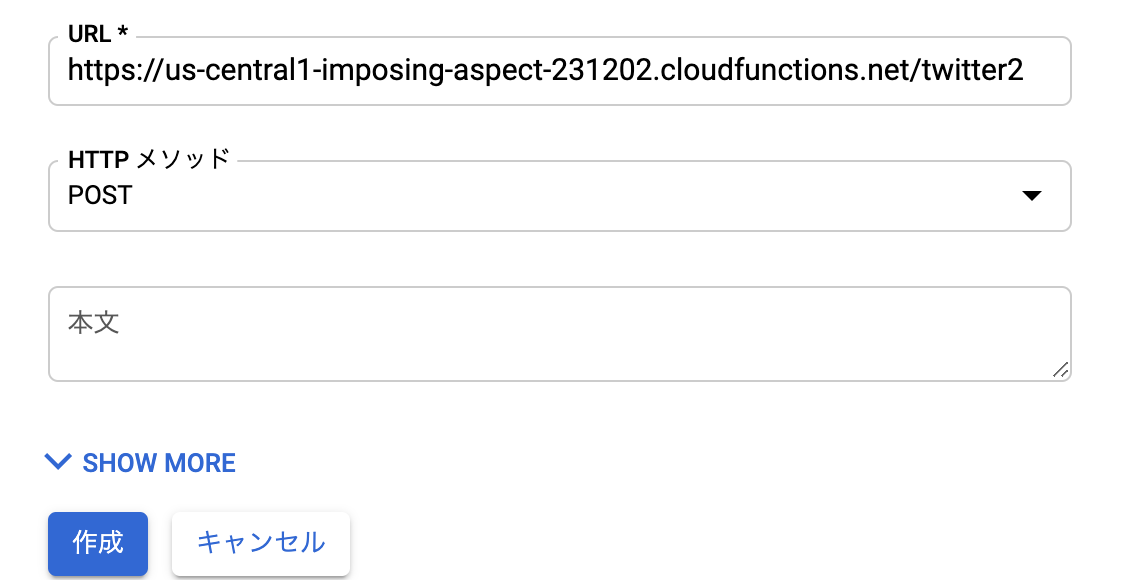
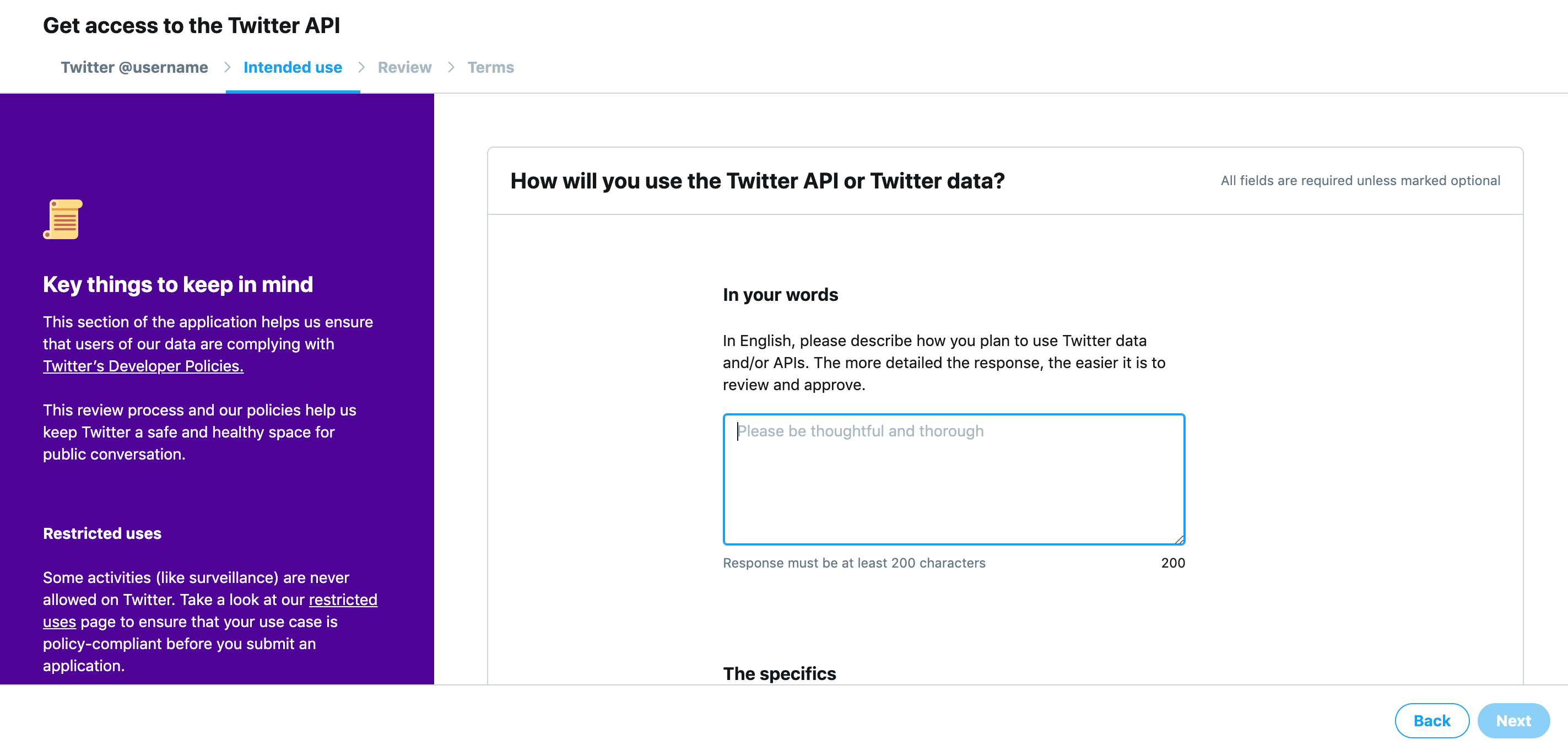
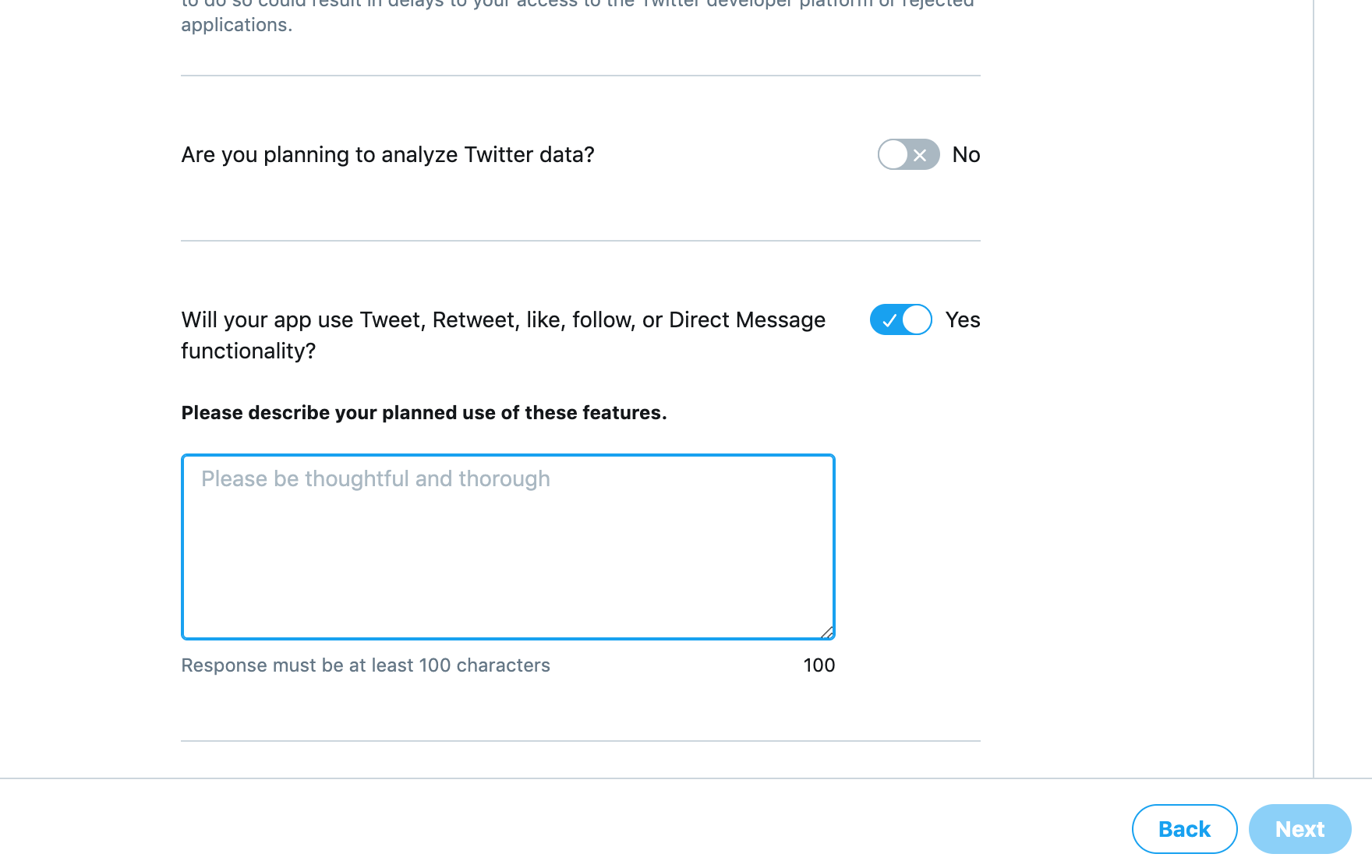
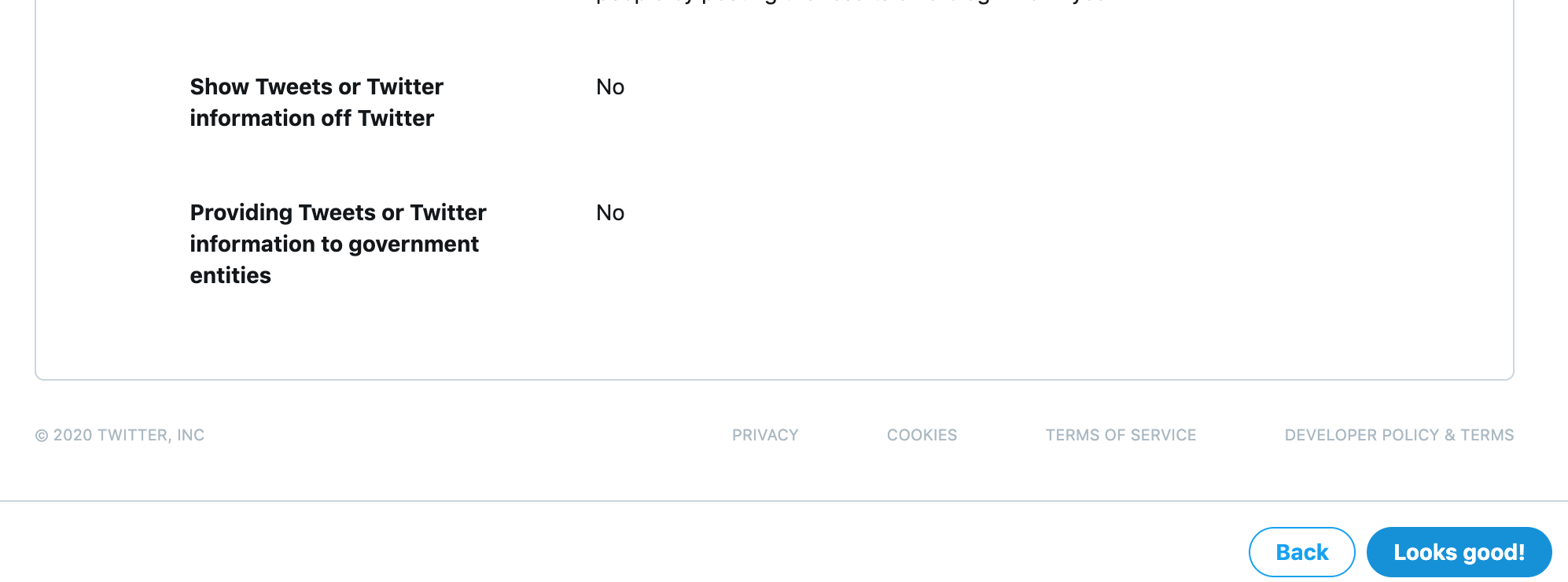
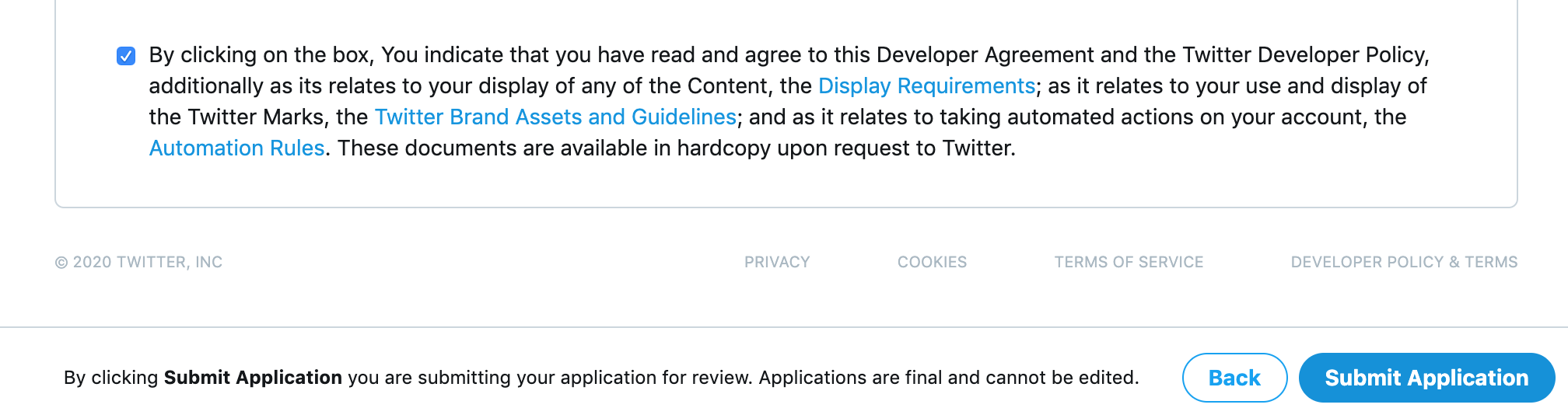
from collections import Counter N = int(input()) S = [] for n in range(N): S.append(input()) c = Counter(S) K = [] for i,(k,v) in enumerate(c.most_common()): if i==0: vmax = v else: if vmax!=v: break K.append(k)
N = int(input()) A = list(map(int, input().split())) defcalc(A,mu):v # 整数のリストと変換後の値の候補 return sum([(a-mu)**2for a in A]) ans = 1e+8# 無限大 for n in range(-100,201): # 解のパターン ans = min(ans, calc(A,n)) print (ans)
別解
数学的に解くこともできる。 Aの平均を求め、その前後の整数が解となりうることがわかる。
1 2 3 4 5 6 7 8 9
from statistics import mean import math N = int(input()) A = list(map(int, input().split())) defcalc(A,mu):# 整数のリストと変換後の値の候補 return sum([(a-mu)**2for a in A]) floor = math.floor(mean(A)) ceil = math.ceil(mean(A)) print (min(calc(A,floor),calc(A,ceil)))